I chose the Best City in Florida dataset to put through various data visualization tools and see what kinds of results could be created. This dataset included information for twenty cities in Florida in regards to several quality-of-life variables. These variables ranged from household income, to literacy rate, to golf, to murder rate.
Working with this particular dataset, I definitely had to think it through and do a bit of manipulation to the way the dataset was processed through certain visualization tools. Using Google Fusion Tables, I imported the dataset Excel sheet and played with the various chart options that this data visualization tool offered. Many of them really didn’t make sense to me, as I wasn’t sure which variables were being shown, what particular numbers meant, etc. I had to do some minor editing of the dataset. For example, I found that I had to change the naming of the first column, as the tool labeled the first column as “col0” when it was actually the column that identified the Florida “city,” but Google Fusion Tables didn’t catch that intuitively.
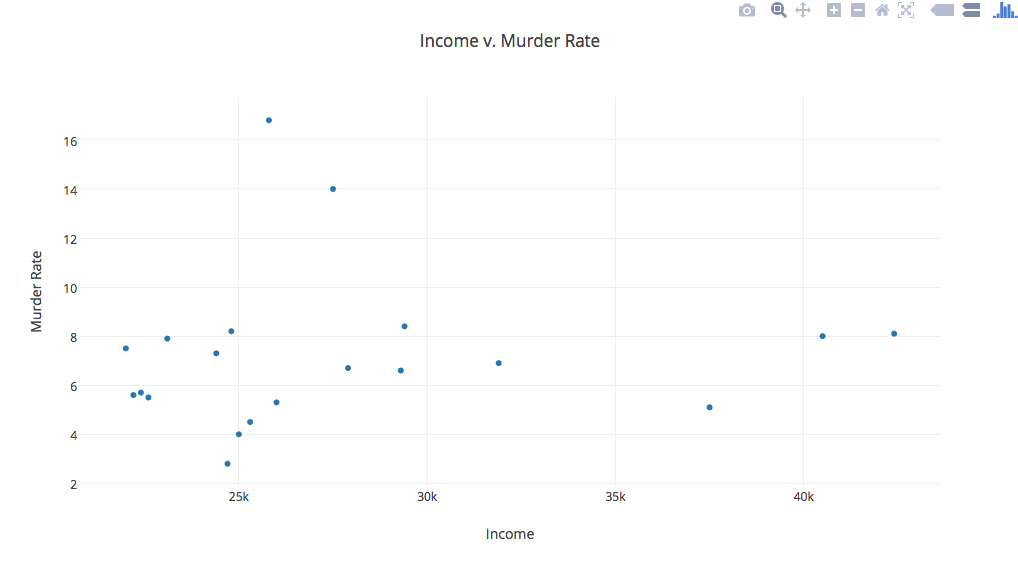
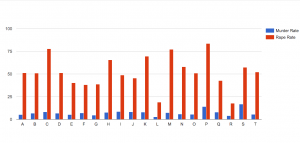
Then, I realized that for each chart/graph you had to choose which particular variables you wanted to focus on. Additionally, only certain ones made visual sense depending on the type of chart/graph. Not purposely trying to be morbid, I chose to analyze and compare murder rates and rape rates within each city. As Yau proposes in “Data Points,” data should be represented “with a combination of visual cues that are scaled, colored, and positioned according to values.” I chose to create a categorical bar chart (Chart 1) that would allow me to do just that to the data. I was able to sort the data by city and put the murder rates and rape rates side by side. However, I first had to change the default number of 10 maximum categories to 20 so as to include all the cities that were in the dataset. After doing that, I could see which cities had the lowest rates of danger vs the cities that had to highest rates of danger. It looks like the city, P, would not be the safest to live in as it has the highest rape rate and the second highest murder rate.
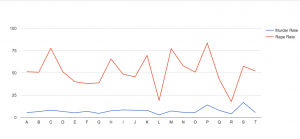
 I also chose to look at the data through another visualization, one that charted lines side-by-side (Chart 2). By doing so, you could visually see in another way the higher murder and rape rates in city P, as both lines relatively spike/peak for the particular P point on the graph.
I also chose to look at the data through another visualization, one that charted lines side-by-side (Chart 2). By doing so, you could visually see in another way the higher murder and rape rates in city P, as both lines relatively spike/peak for the particular P point on the graph.
Putting this particular dataset through thses visualization tools illuminated certain aspects of the data that I couldn’t see through just the excel sheet, like which city has acquired the highest rates of danger (murder and rape), as compared to the other Florida cities included in this study. This exercise was definitely way more challenging than I expected. I’ve learned that all kinds of decision-making goes into data visualization, way more than I initially thought. You can’t just import an excel sheet into these tools and magically create comprehensive charts and graphs that make sense. You really have to know and understand what variables you want to focus on and visualize, as well as understand the kinds of visualizations you want to make and which make sense with the data you have on hand.