I took a look at the L.A. Controller’s Office’s report on their city departments and payrolls, because I was interested to see how funds are allocated, and therefore, examine what is deemed the most “important” or “necessary” by the City of Los Angeles.
It can be accessed by clicking the image below.
The Data Types
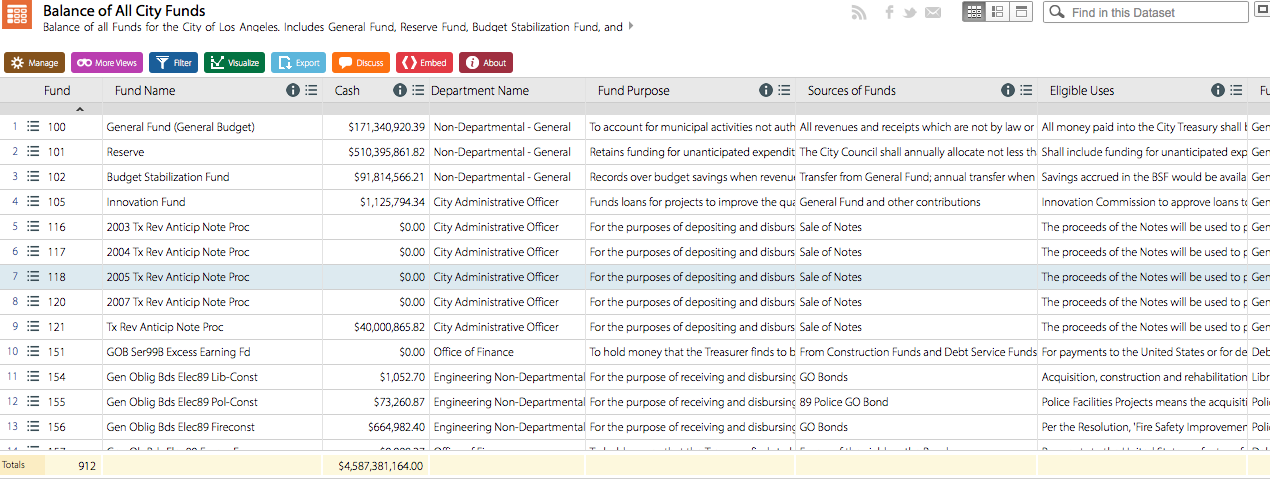
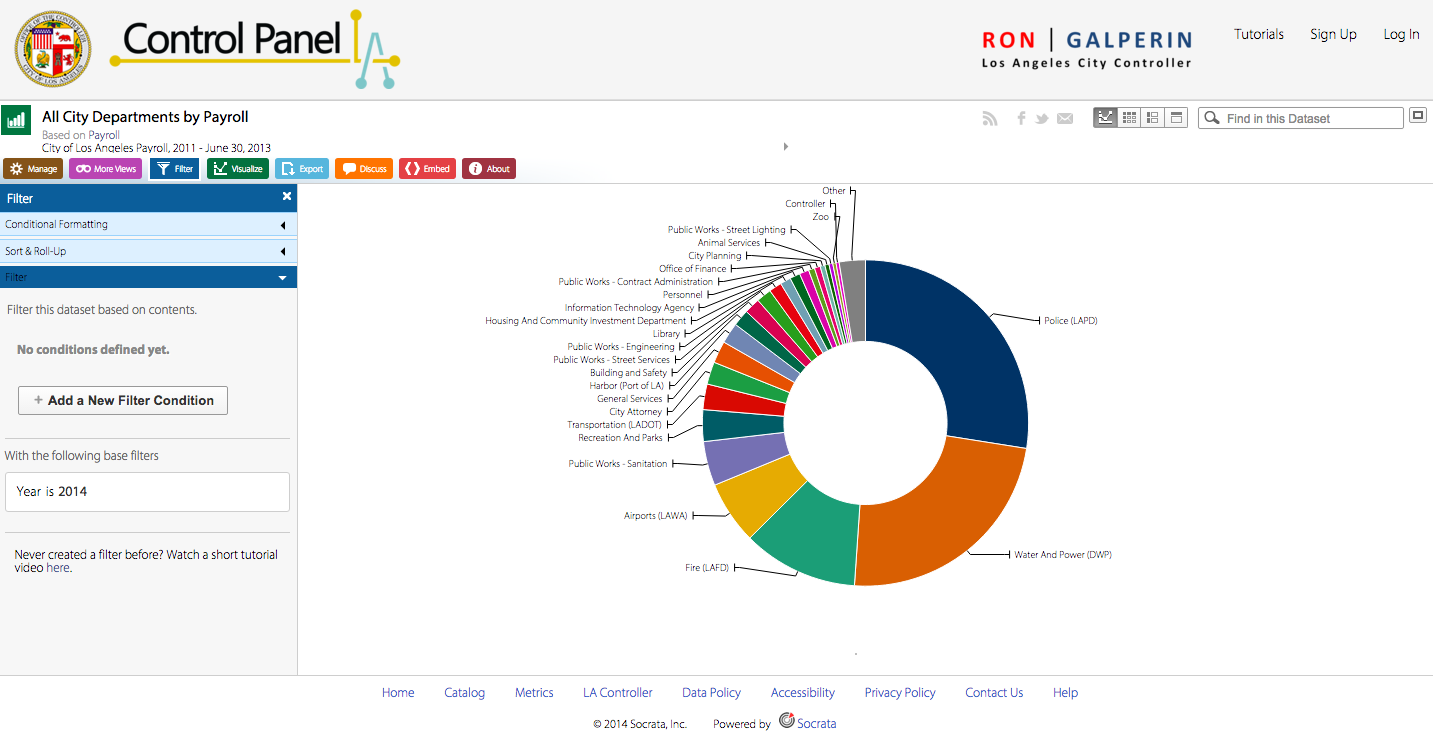
The data represents the payrolls of all city departments from 2011 to June 30th of 2013. These numbers show how much taxpayer money the departments received for their services, whether they be Parks and Recreation or LAPD.
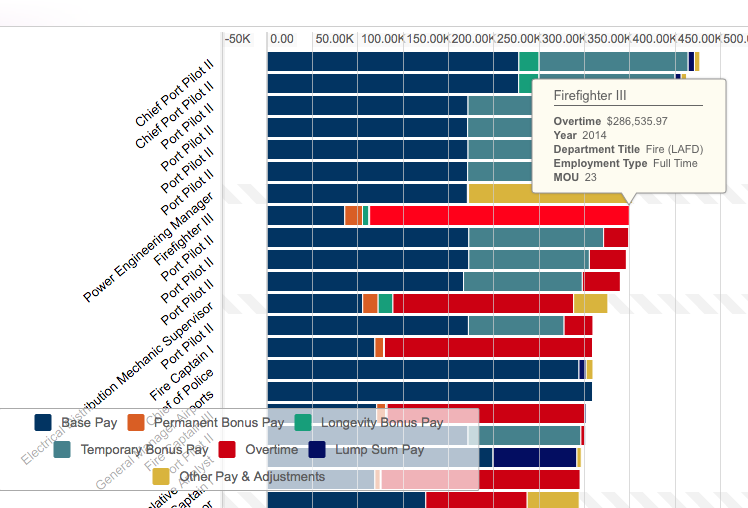
Each record in this dataset is considered the department name, and the corresponding payroll number in dollars. There are not many dimensions to this dataset–it focuses on these two aspects, without specific breakdowns for details like number of employees. This data may be accessible elsewhere on the site, but does not show up directly on the visualizations.
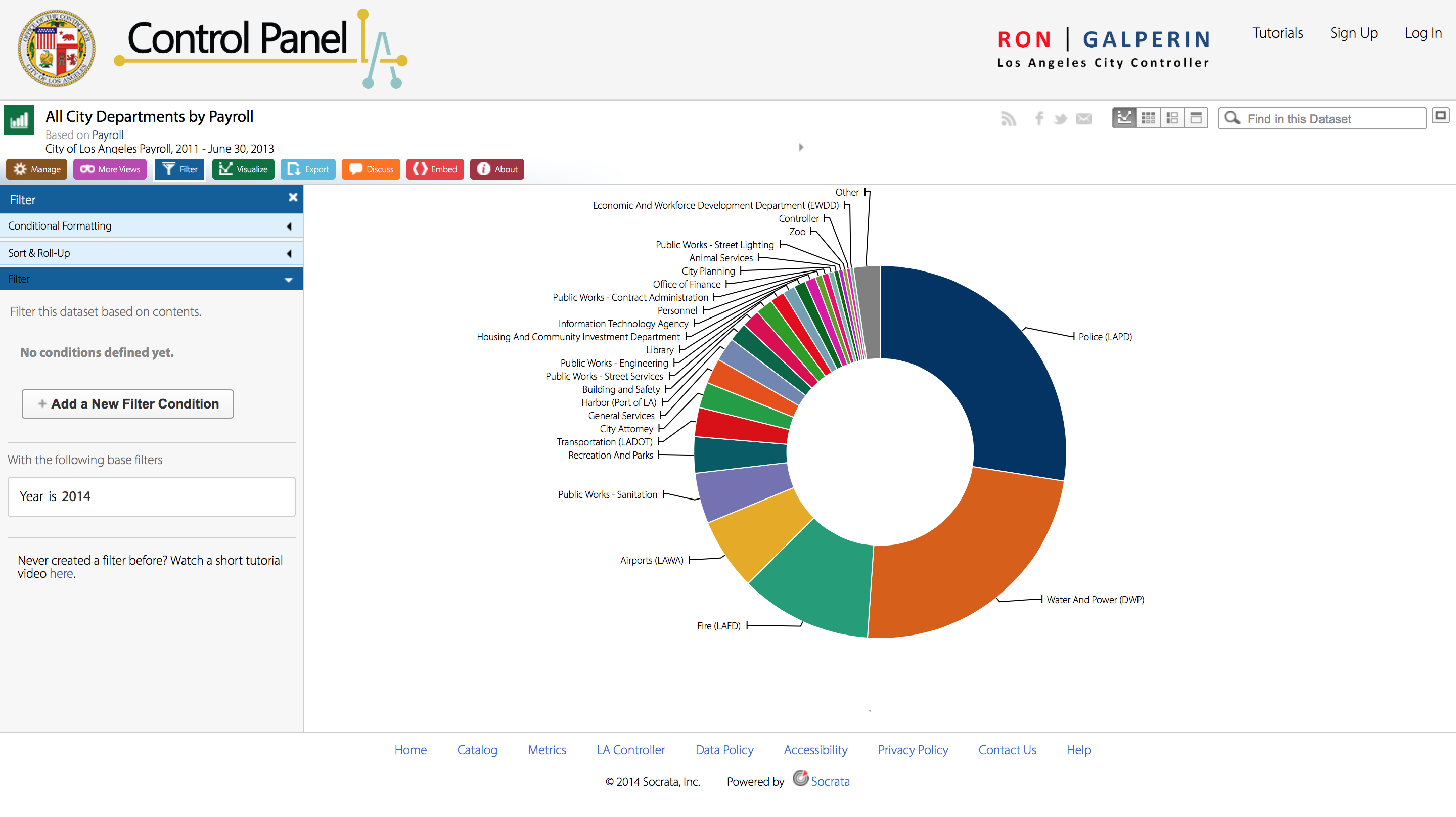
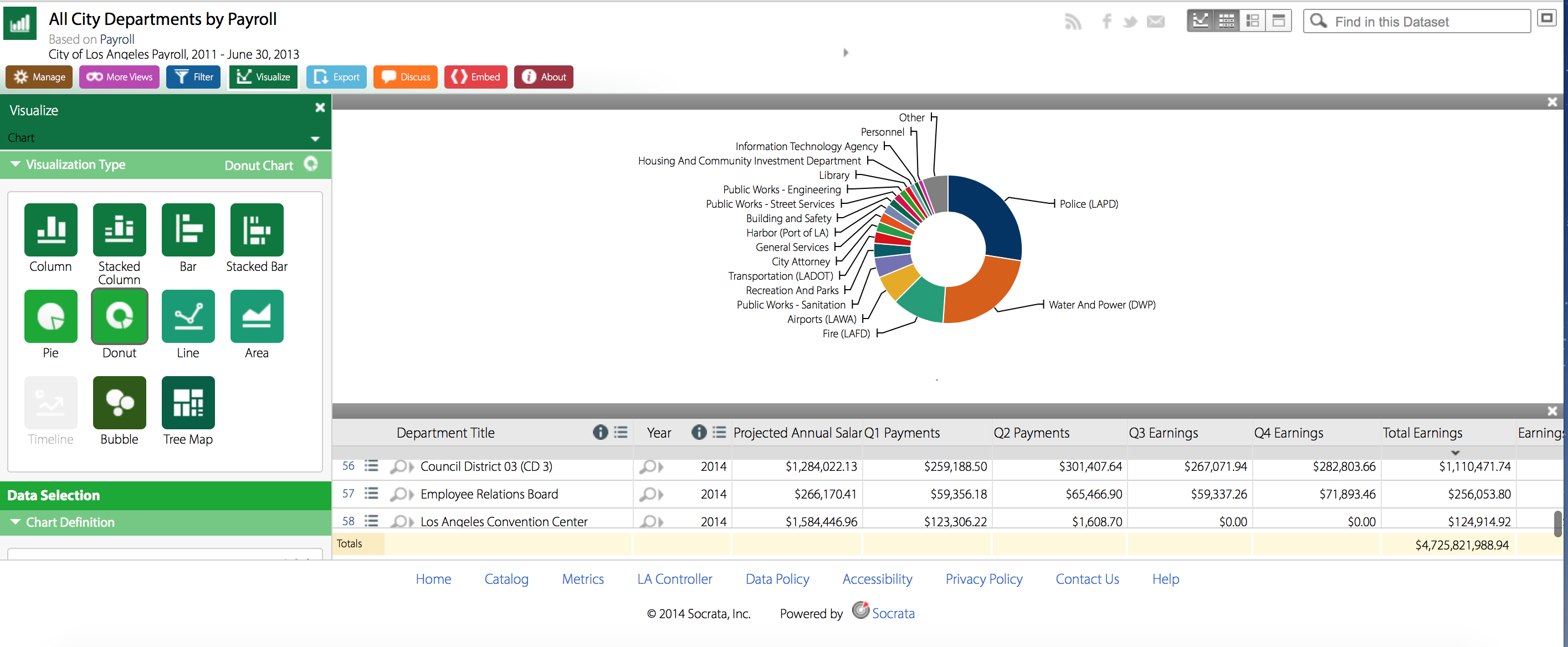
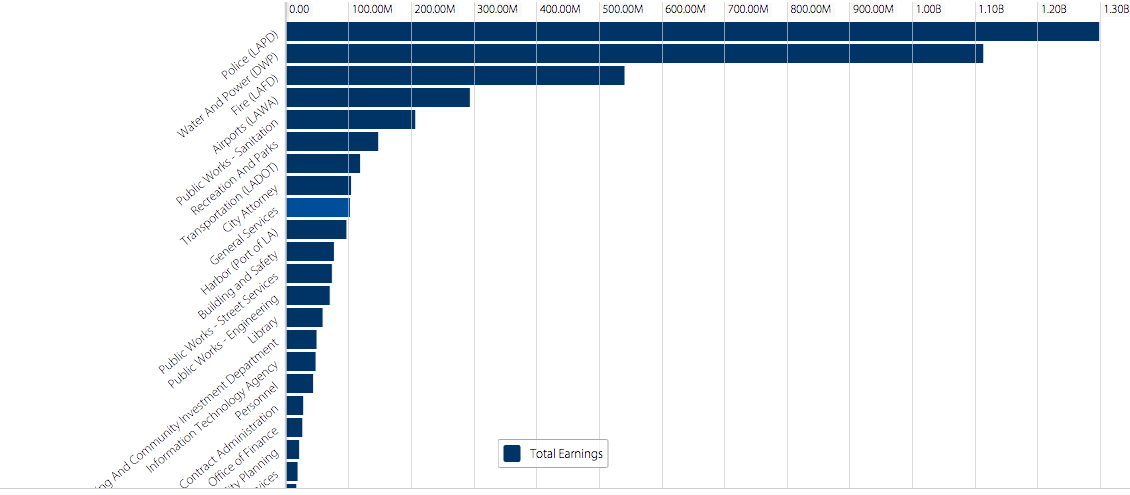
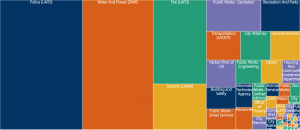
There are a wealth of data visualization options here, ranging from “donut” charts to stacked bar charts to “tree maps.” Regardless of which option the user chooses, there is a clear trend in the data–departments like LAPD, DWP, and LAFD dominate the payrolls, taking up more area or larger bars than smaller departments like Cultural Affairs or the Employee Relations Board. While the UI for finding and sorting this data may not be the most intuitive, it’s great that the Office included this level of variety.
The Ontology
According to the paper by Wallack and Srinivasan, data ontologies are “systems of categories and their interrelations by which groups order and manage information about the people, places, things, and events around them.” Ontology describes how people categorize data into different structures, based on their social, cultural, and experiential backgrounds. Though there is not a lot of raw information here, the data’s ontology divides the data into departments and payroll amounts, categorized by the City of Los Angeles. It is difficult to extrapolate on the social, cultural, or even financial reasons behind the way this website presents its data, especially because it seems so limited, but this fact in of itself may hint at the motivations.
This data is useful for any taxpayer in Los Angeles County to see where their money is going, and how it is prioritized, but may be the most illuminating to the workers in these departments. I am sure employee wages and departmental funding are sensitive topics for many, so the substantial differences in the payrolls may exacerbate frustrations or inspire change. This data may be useful to build a numerical and visual argument for increased funding in smaller, but still important, departments.
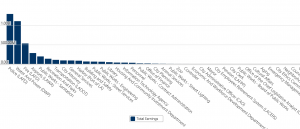
The Data Set
This data set elucidates the vast differences in each city department’s payroll. It is surprising, especially when displayed in such a visual manner, that LAPD receives around 25% of the whole city’s employee payroll. Meanwhile, departments like Housing And Community Investment or Libraries receive a much smaller chunk.
I am conflicted on how to interpret this data. On one hand, I understand that the safety and protection of the citizens of LA should be the highest priority. Or that without efficient water and power systems, the city would lose productivity. However, the large numbers make me question how efficient these systems even are. Large organizations tend to be slow and bureaucratic (especially in government!), and I’m curious to see how much of taxpayer money is being put to good use. Furthermore, I find it interesting that the troublesome aspects of LA, like a terrible public transportation system or education disparities, which may be handled or improved by departments like Transportation or Libraries, do not seem well funded.
However, I do think it’s important to have more contextual details and further data before coming to conclusions. Information like year-by-year funding changes, number of employees, hours worked, and sub-departmental distributions may be helpful in constructing an argument for either side.
The New Ontology
As is, this data, while interesting, is incomplete. It contains numbers that are not fully contextualized or explained, making it difficult to come to conclusions. A new ontology would include a breakdown of how the funds are spent to see how money is distributed within the department. Information about requested funds against received funds may be useful as well. These would help taxpayers understand whether the payrolls, whether high or low, are justified.