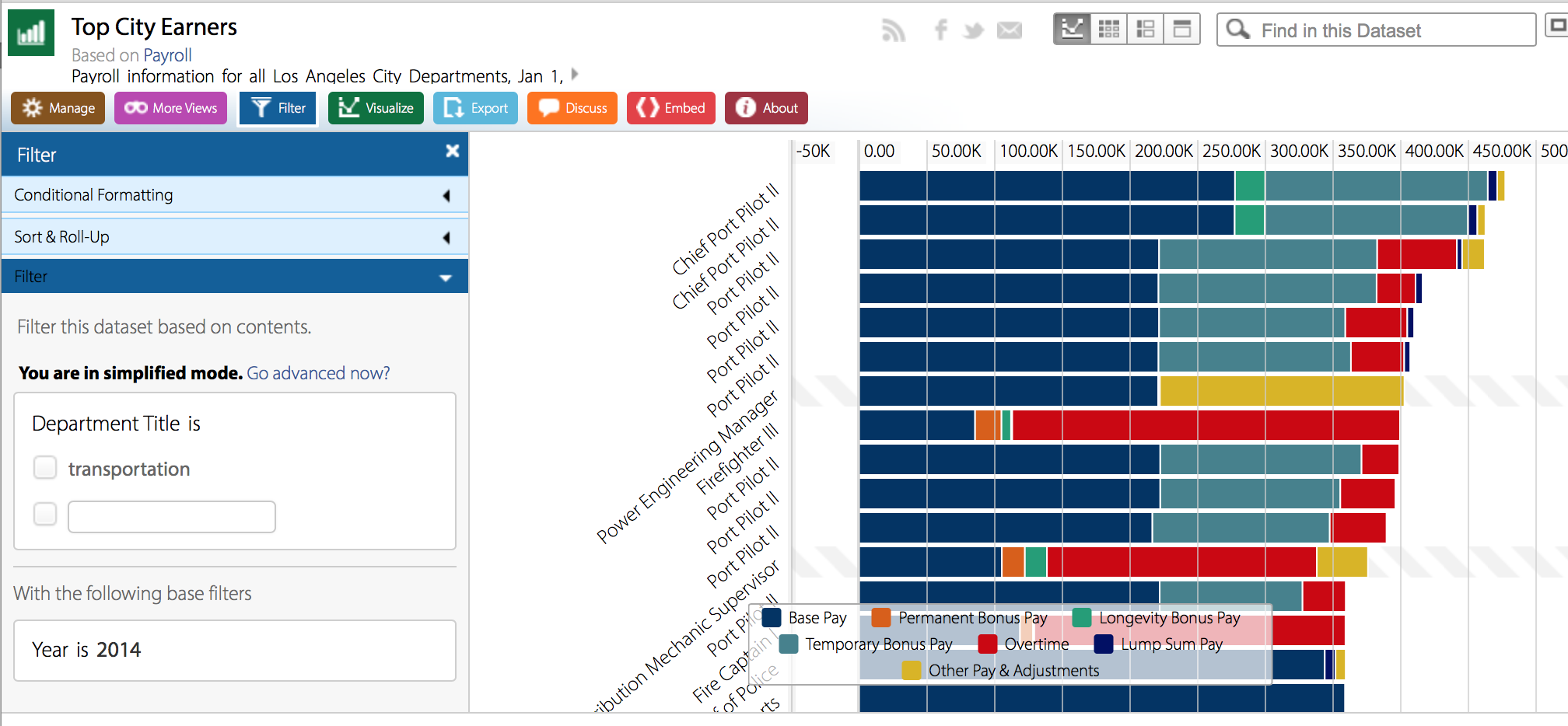
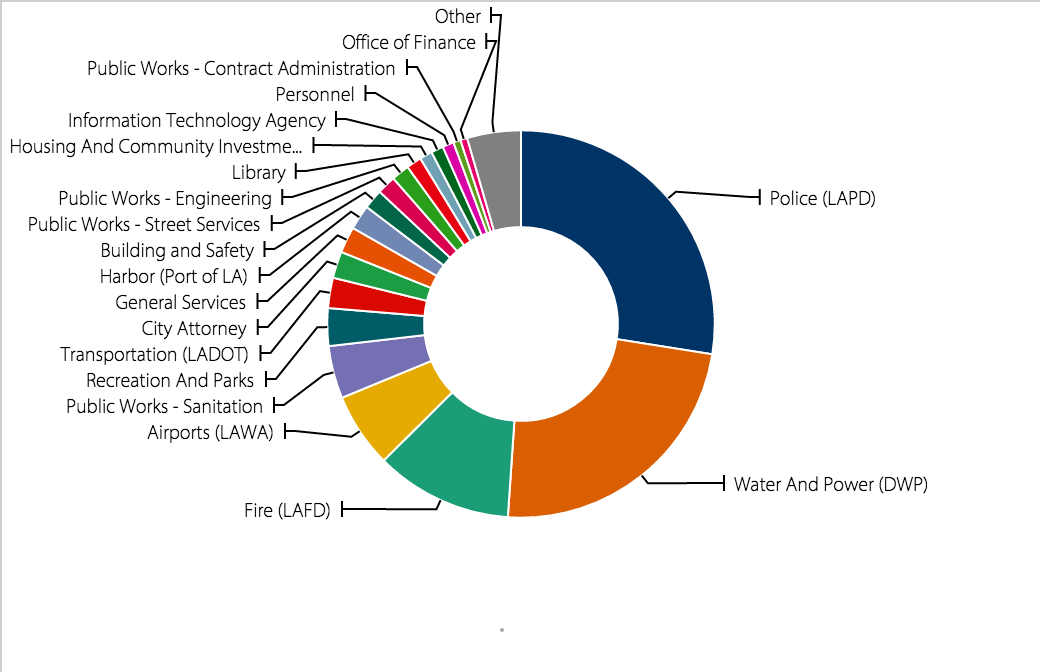
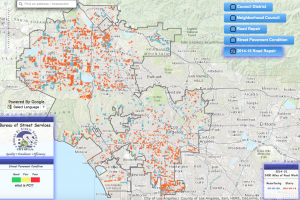
Grades are often the bane of a student’s existence, but the pressure of grading does not end with the education system; rather, grades are assigned to many things in life, from eggs to Olympic performances. Roads also fall in this category, as evidenced by the L.A. Controller Office’s data set entitled “Street Grades.” This audit report contains information about the state and quality of roads provided by the City of L.A.’s Bureau of Street Services.
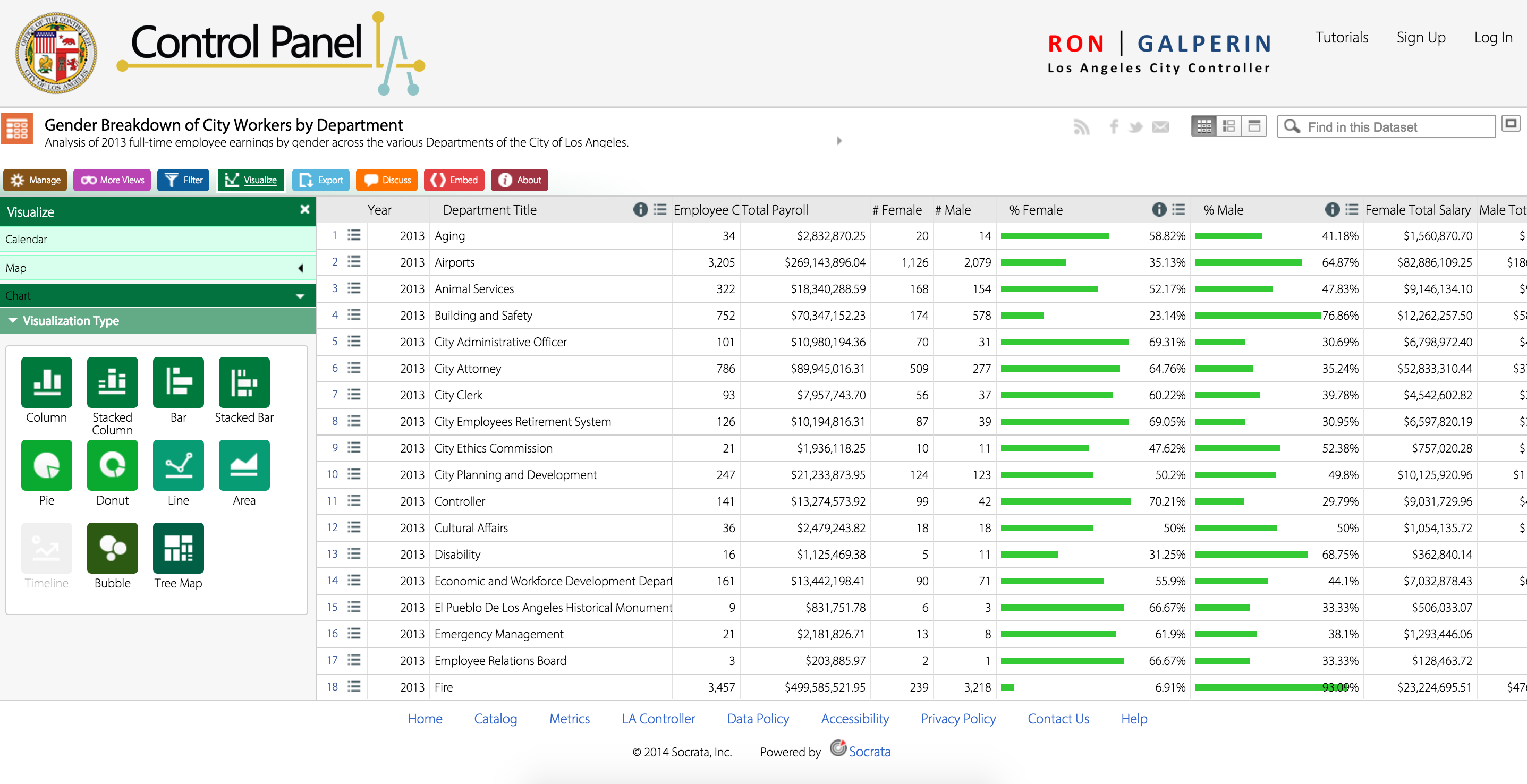
This project uses data visualization in the form of a large interactive map. It provides the ability to zoom in and out, and explore the innermost regions or outermost corners of the L.A. county. The map also has five different available features for classifying its data that can be grouped into three data types: council boundaries, road conditions, and road repair. In the upper right-hand side of the page, these categories can be toggled on and off to present different information to the viewer. The two council boundary categories include smaller neighborhood borders, as well as larger council districts. The road repair options can either show previous roadwork completed in the 2014-2015 period, or more recent and proposed roadwork for 2015-2016. In this data set, a record is an individual road, which can be classified by its current condition, work that has been done on the road, or work that is proposed to be completed on the road.
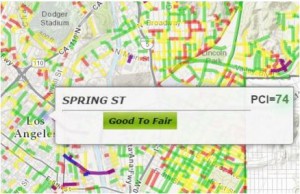
The Street Pavement Condition option is the core feature of this data set, as it provides data about the quality of the majority of the roads in Los Angeles. Each road is ranked based on the Pavement Condition Index, or PCI for short. This ranking works on a 0-100 scale that is based on combined consideration of the road’s current physical condition (e.g. whether there is cracking or base failure) and the maintenance required to get the road to an ideal condition (e.g. slurry surfacing).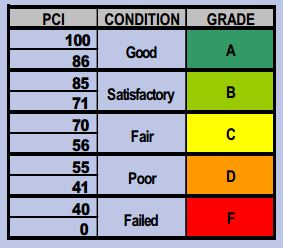
Therefore, the PCI becomes the data set’s ontology, since it falls under Wallack and Srinivasan’s definition as a system of categories by which groups order and manage information about the things around them. The PCI provides valuable information for viewers by assigning comprehensible terms that have widely agreed upon definitions to the 0-100 scale: failed, poor, fair, satisfactory, and good. By taking numerical values and equating them to terms that make sense to the general public, this data is easily understandable, and therefore useful for a wide range of people.
The groups that are most likely to find the data illuminating are encompassed by the categorized districts on the map: neighborhood and city councils. Neighborhoods are obviously invested in the quality of their home environment, and they can petition the city council to fix problems that arise, such as roadwork. If a neighborhood council or the neighborhood watch notices that some of their roads are damaged to the point of being dangerous – causing tripping hazards, making it hard for kids to ride bikes – then they can use this resource to write an informed petition for funding to fix the roads. This data provides evidence that goes beyond photographs and unhappy testimonies from people in the neighborhood. Similarly, when city roads get potholes or cracks that start to affect the driving experience of large numbers of citizens, this resource can provide necessary context for city councils to get funding to fix the roads.
Looking at this data, it can easily be discerned that many, many streets in L.A. are in poor condition. And yet relatively very few have proposals to  be repaired. This can likely be attributed to a conflict of public interest; people want good quality roads in their area, but are reticent to pay the fees to fund said repair. Branching off this notion, it seems that areas with high concentrations of poor quality streets sometimes do not have any proposed or scheduled repairs, possibly because the area is impoverished.
be repaired. This can likely be attributed to a conflict of public interest; people want good quality roads in their area, but are reticent to pay the fees to fund said repair. Branching off this notion, it seems that areas with high concentrations of poor quality streets sometimes do not have any proposed or scheduled repairs, possibly because the area is impoverished.
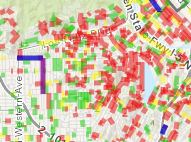
Conversely, areas with higher concentrations of “good” and “fair” streets have more reconstruction project scheduled, likely because they are more affluent areas that can afford to spend money on such projects. While this does make economic sense, seeing such patterns certainly does not feel good or fair.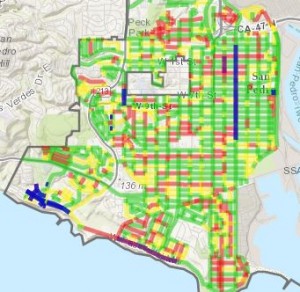
Though this data set provides a lot of valuable information, some information is still left out. There are some roads on the map that do not even have PCI ratings, like the canyon roads that run through the mountains. Even though these roads probably see less use than city or neighborhood streets, mountain passages can be more hazardous than typical roads and deserve attention. This data also does not include information about highways or freeways, or other paved areas like parking lots. And while it does contain proposed road resurfacing projects for 2015-2016, it does not contain indication of public opinion – e.g. whether some neighborhoods are trying to get propositions finalized but are facing opposition or setbacks.
If this data collection were to be redone, it could be described from a couple new different ontologies. One perspective would be that of safety organizations or neighborhood parents, who might forgo the “poor, fair, good” categorizations for terms that are directly correlated to safety, e.g. “hazardous, requires caution, safe.” While the current ontology does have implications for safety – a road ranked as “poor” logically will be less safe or pleasant to drive on than a road ranked as “good” – this adapted ontology has stronger implications. Another ontological perspective could be that of local government, who might just use two groupings based on an economic viewpoint, categorizing streets as either “requires attention” or “does not require attention.” This narrows down the classifications of road status and creates a simplified way of identifying whether funding really needs to go towards repairing a street, or whether it is usable in its current state so that attention can be focused elsewhere. Still, I believe the current data’s PCI grading system is functional and approachable for a wide range of people, and does not require an ontological overhaul.