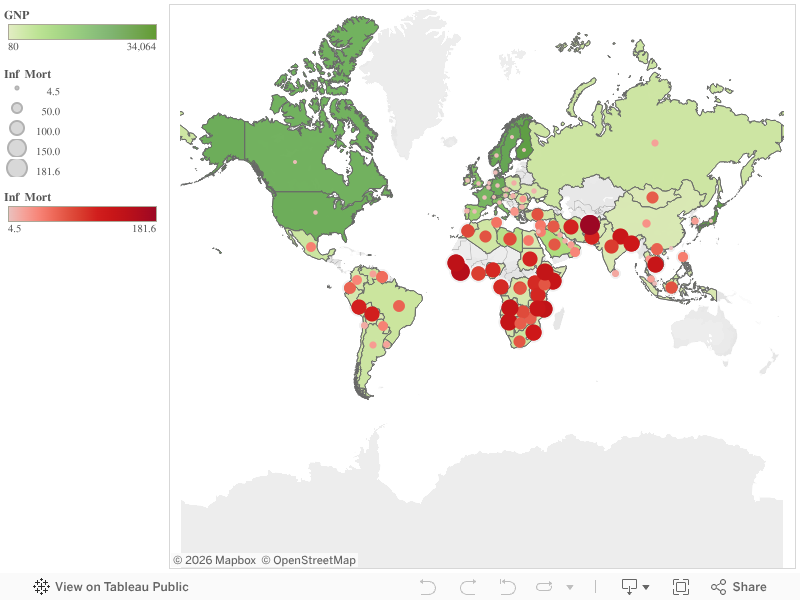
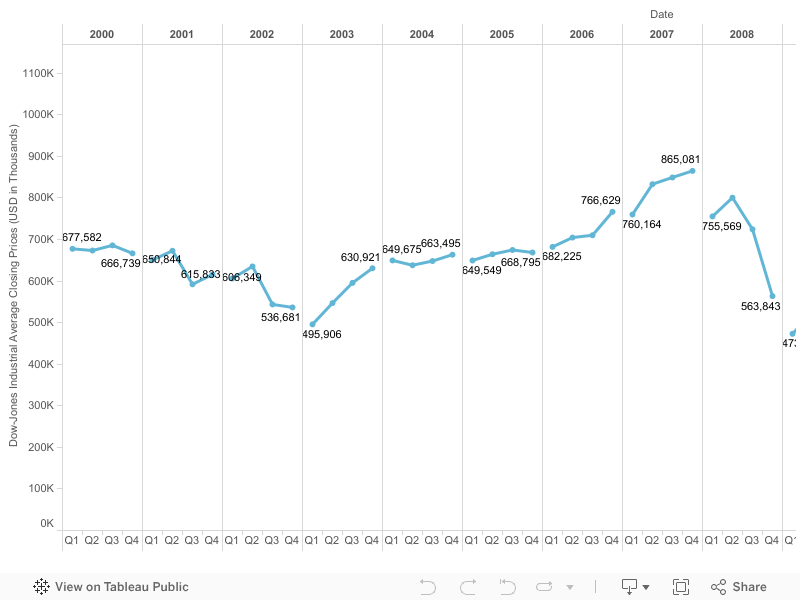
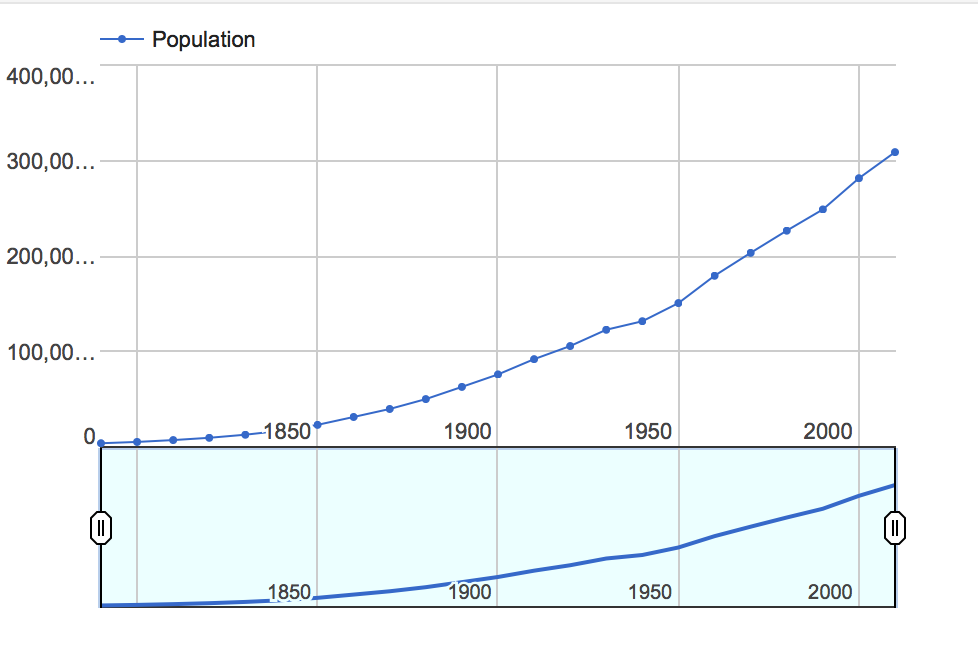
This week’s topics were a bit challenging, as there are quite literally hundreds of ways to create data visualizations! With so many options, it did get a bit overwhelming, but as the week progressed I found myself to understand them a little better. With data visualizations, it is important to first look at the data and find visualizations that will best interpret it. I had a chance to experiment and do this with one dataset, aptly called Titanic, which has data from the first– and last– voyage of the famous Titanic. A rather simple dataset, the file proved more difficult to interpret and demonstrate as a visual than initially thought.
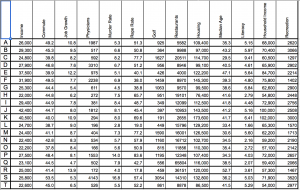
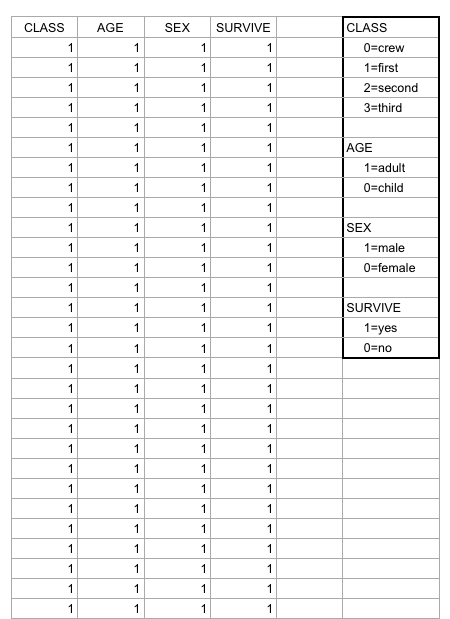
Right off the bat, as I opened the Titanic.XLS file, I noticed that the data was numerical; however, the numbers actually represented qualitative, categorical data! For example, documenting the passengers’ ages with 0 for child, or 1 for adult; a 0 for female, 1 for male, so on and so forth. I thought that although pretty smart in making the records easier to read in general, especially with the legend present on the side, transferring the file into a visualization tool turned out to be more problematic than it seemed.
According to Yau in “Data Points,” data should be represented “with a combination of visual cues that are scaled, colored, and positioned according to values.” Keeping that in mind, I decided to use RAW for this dataset, as I felt that the multiple choices and customization options of the visualization tools it offers was fitting with the data I chose. Since the numbers in each content type did stand for something else, I felt that an alluvial diagram best fit the data, as this method of visualization represents flows and correlations between categorical data. Therefore, I went ahead and plugged the file into RAW. And that’s where I encountered some problems…
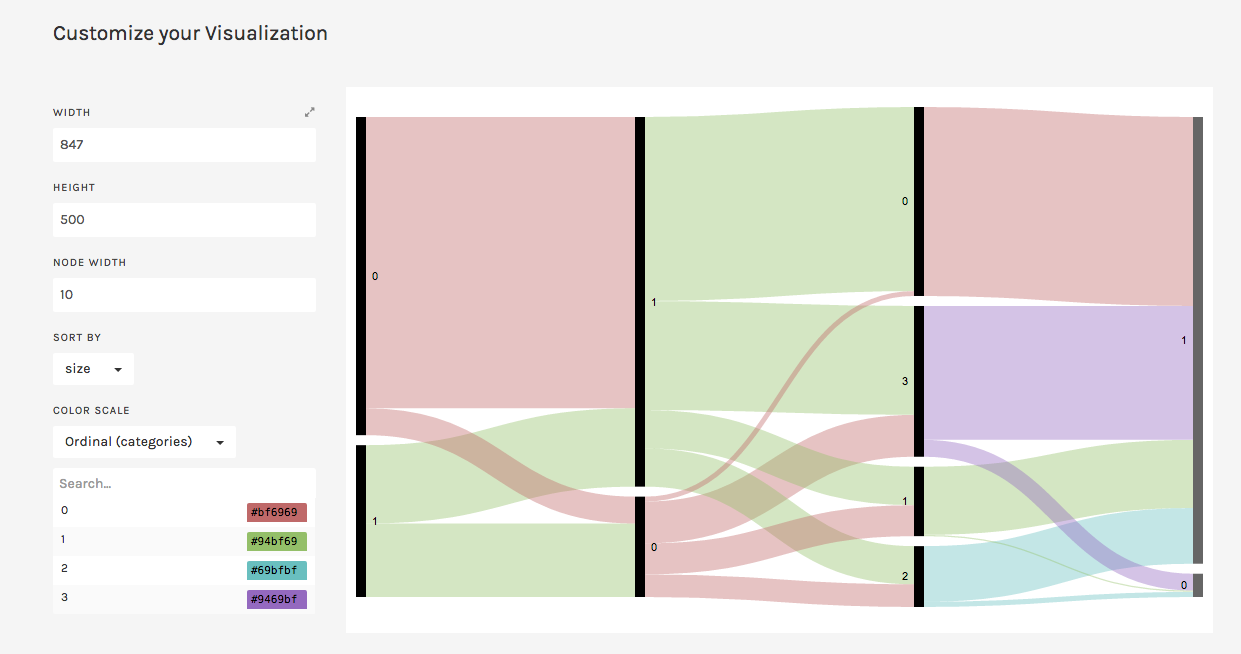
WHAT HAPPENED?!
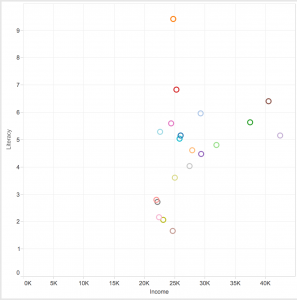
This is where I realized that something was wrong– well, not wrong, but off! I figured that because the original data used the 1’s and 0’s as markers for other meanings, it then translated into the alluvial diagram. Above, it’s pretty evident that although the data is there, the categories aren’t even labeled, but just left with the markers.
At this point I had also tried different visualizations on the site, but they all yielded the same results as the alluvial diagram with only 0’s and 1’s. I figured that the only way to really illuminate this data is to go back to the original Titanic.XLS file and change the numerical markers to their intended meanings; this meant that I would change the 0 representing female passengers to “Female,” and the 1 representing male passengers to “Male.”
Luckily, I was able to do this in no time on Excel; though afterwards I realized that it may have been even more time-saving if I had used OpenRefine! So now, with the data practically cleaned and more able to be transferred onto RAW, I replugged the adjusted dataset and tried the alluvial diagram again.

“Visualization is what happens when you make the jump from raw data to bar graphs, line charts, and dot plots.” – Yau, Ch.3
This time, it was a success! Now, one can view the correct categories for the content: starting with class, then age (adult or child), filtering down into sex, and finally if the individual had survived or not. Looking at the diagram, it is extremely clear to see the data, which itself was startling as I was cleaning and transferring it. Most of the passengers who had died were adult males, coming from the ship crew and most of the Third Class. What’s even sadder is that, although a very small amount, some male children did not survive.
In conclusion, I am happy to say that practicing with this dataset helped me better grasp what data visualization is and how it enhances data. By having something physically representative to put into perspective, I feel that one can really see how much of an impact (no pun intended) such data poses on human history; in this case, the tragedy of the Titanic is still as shocking and eye-opening as it was a hundred years ago.With that being said, the visualization tools presented to us definitely help to emphasize the importance of recording, archiving, and preserving human experiences of all kinds.