
- Identify its data types & What constitutes a record in this dataset?
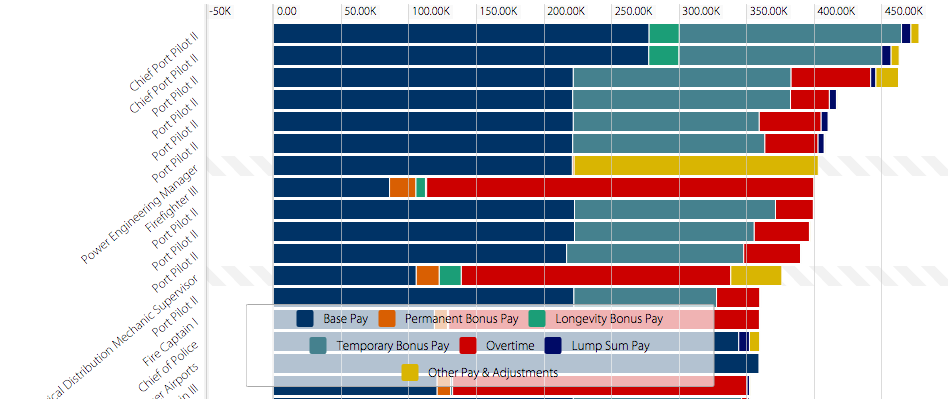
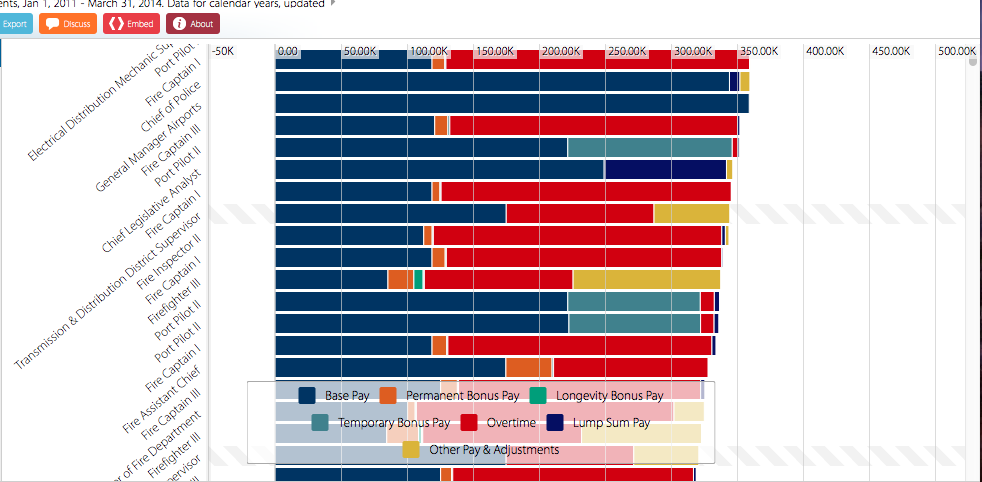
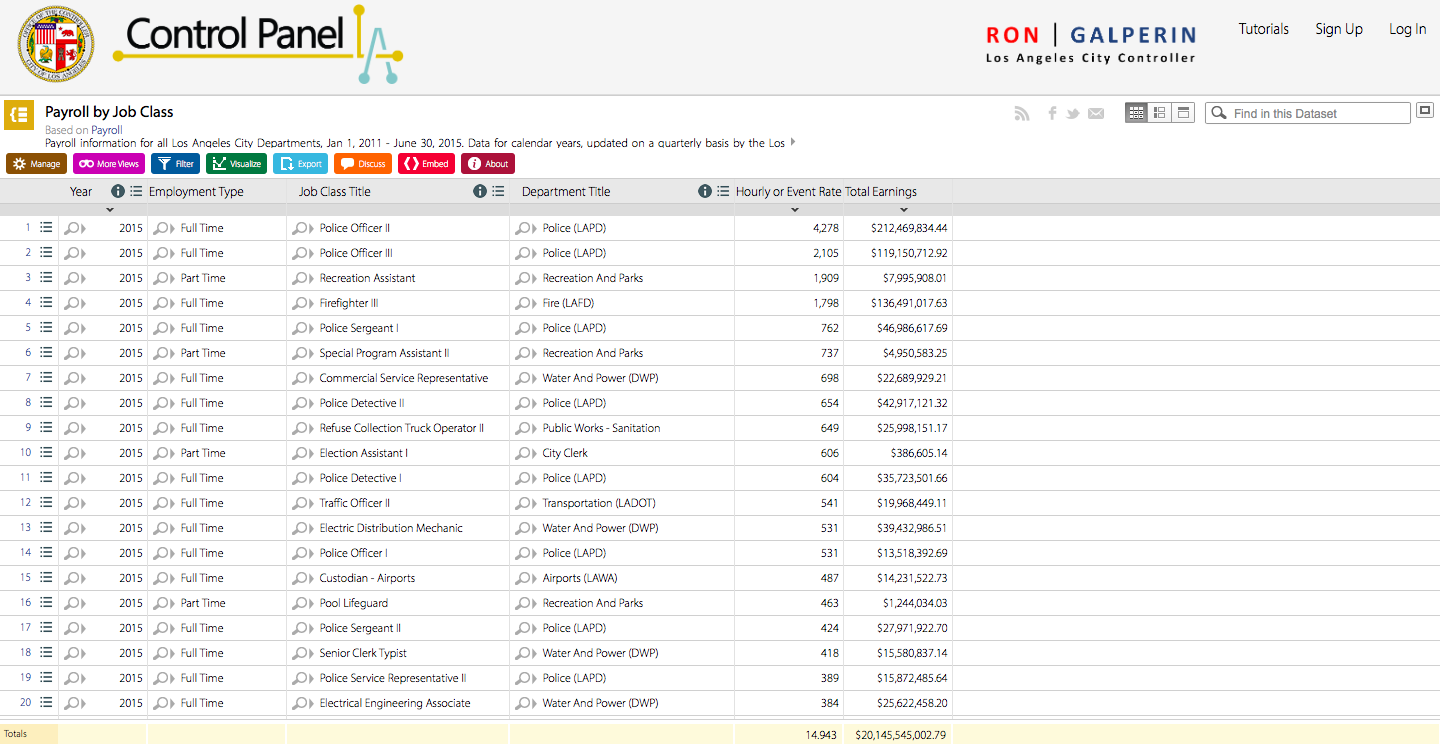
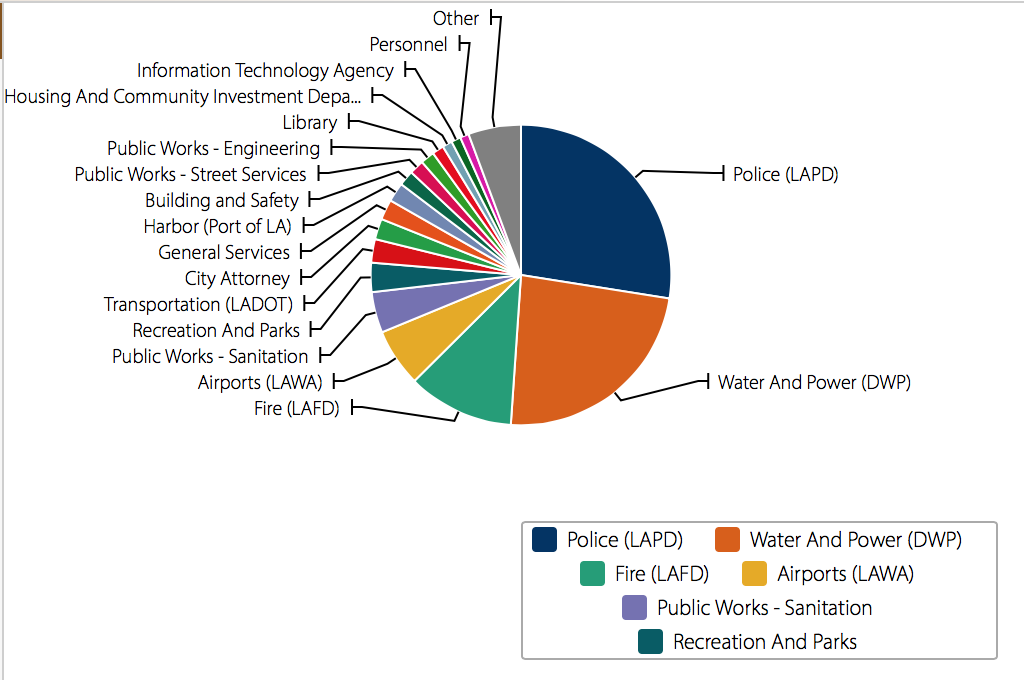
I chose to analyze the Top City Earners dataset from the L.A. Controller’s Office. This dataset represents information about salary for various city positions. The data type is essentially the salary data and, because of the way it’s organized and presented in this table, it’s also possible to compare individual records to each other based on attributes such as base pay, bonus pay, temporary bonus pay, overtime, etc. (these are color-coded, and you can see the exact amounts by hovering over with your mouse). The content model is the salaries, increasing by $20K for each consecutive column. The record for this dataset is the job title, organized from highest to lowest-paying positions, and also alphabetically and by department. Overall, the data list is very large, but quite appealing and interactive in the way it’s presented.
- Use Wallack’s and Srinivasan’s definition to identify the dataset’s ontology.
In their article on mismatched state and community ontologies, Wallack and Srinivasan described a ontologies as “systems of categories and their interrelations by which groups order and manage information about the people, places, things, and events around them”. Put differently, an ontology is a way of representing data so that you can see more easily if there are particular relationships and/or patterns among the various categories. The ontology for this dataset is salary amounts and types for different positions.
- From whose point of view does this ontology make the most sense? (Another way to ask this question: Who will find this data most useful and illuminating?)
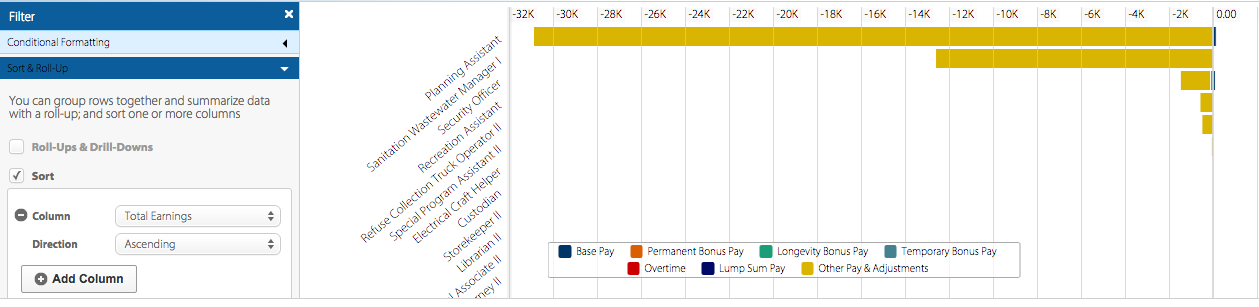
This dataset seems to be useful for community members looking at jobs and salaries in the city. It’s helpful both for people currently employed and looking for a raise, or for potential employees. On the left side, you can filter the options. The filter, however, doesn’t seem to be very well made because typing “transportation” into the simple search box, for example, yields no results although there’s undoubtedly several jobs in transportation with the city. The Advanced Filter option is programmed a little better as it allows for narrower searches.
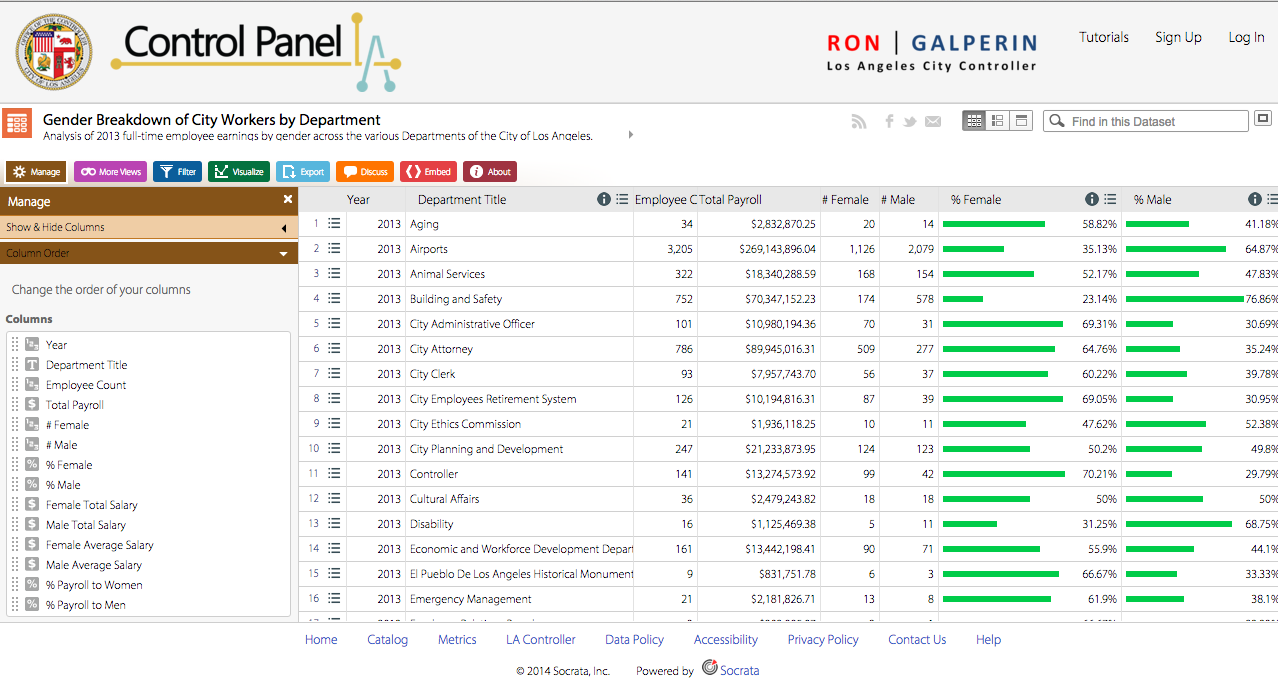
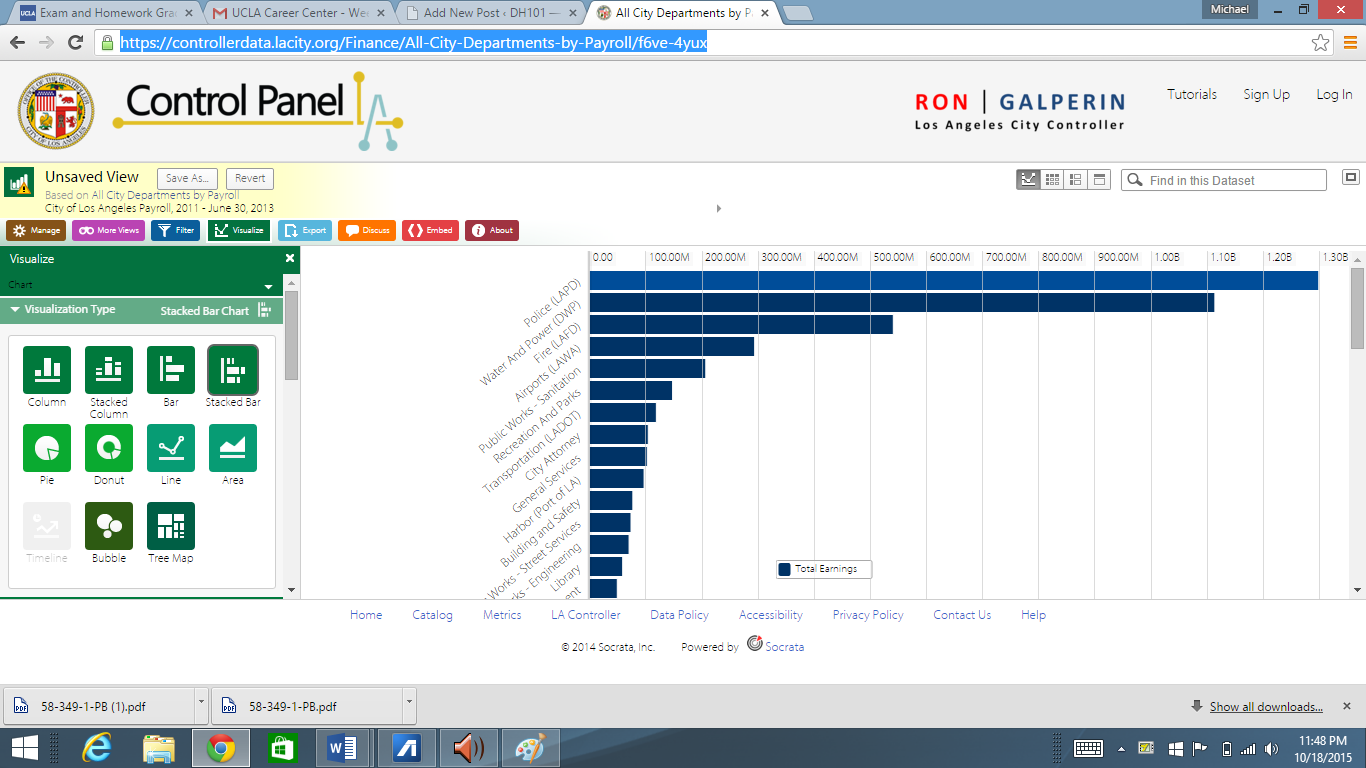
Furthermore, the dataset could be useful for city officials to know how the salary budget is being allocated and which positions demand higher base pay and which positions rely more on overtime pay.
- What can this dataset tell you about the phenomenon it claims to describe?
The dataset most definitely shows what it was intended to. By looking at the top twenty or so records, we can see that the top earners in the city are Chief Port Pilots. This amount, however, includes a large portion of temporary bonus pay (turquoise bars) in addition to base pay (navy blue). But if we look only at the base pay, the Chief Manager Airports actually is paid more. So, it’s important to keep these attributional details in mind when interpreting this table.
- What gets left out?
Perhaps adding a category to organize job salaries by zip-code would be helpful. There may be notable salary differences for the same positions for people working in Central L.A. versus people working in Culver City or Norwalk.
- Imagine you’re starting over with data-collection and describe a completely different ontology, from someone else’s point of view.
The dataset seems to accommodate both city officials to see how salary budget is being allocated and for community members looking for jobs with the city. If I were to collect the data from scratch, I would also include the average hours per week that people in these positions work. I would probably include this information in the little text bubble that pops up when you hover over the record with your mouse. In addition, I’d also look into possible gender differences and educational differences. These could be added to the records, so for each position, there’d be additional records corresponding to gender and level of education.



{kind=link}