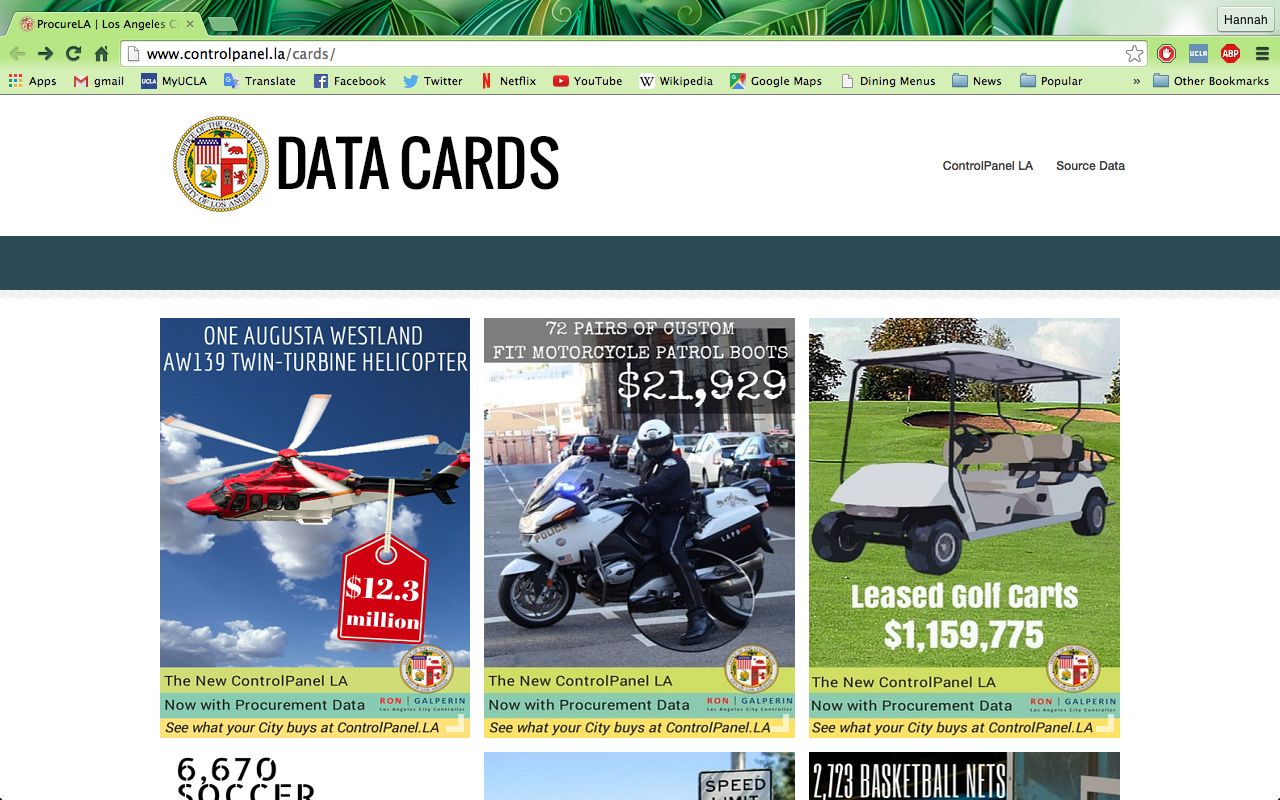
Today I had a look at the LA Controller’s Office . The great thing about this site is that it is all “Open Data”– that is, data is made accessible to the public. People are able to open, download, and shared regardless of any relationship with the LA Controller’s Office.
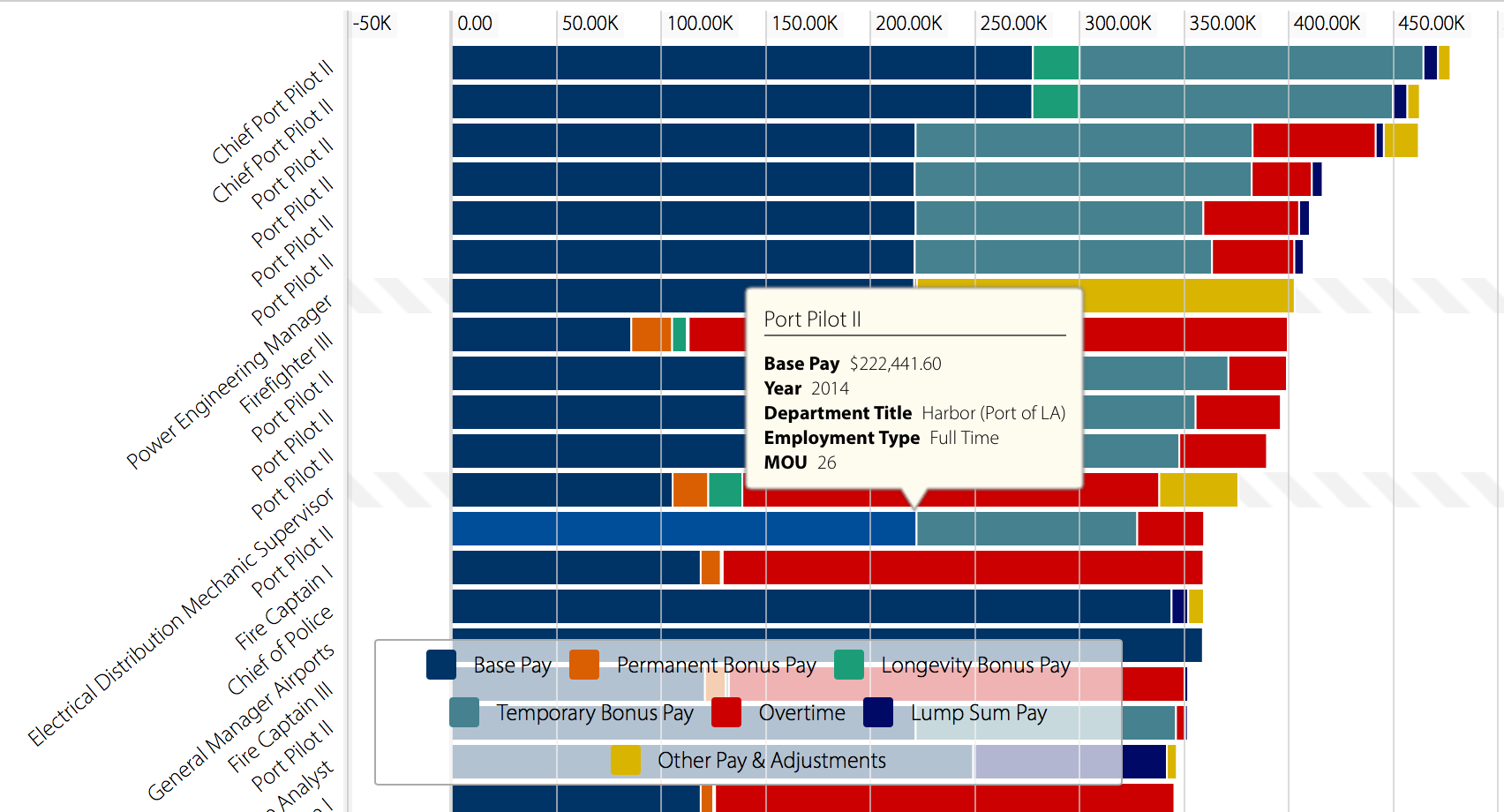
I chose to dig into the Top Earners category, and right off the bat, I can tell that this dataset would be an interesting one, given that the first thing I saw was a massive bar chart! The purpose of one of the data types being a bar chart is to demonstrate the maximum earnings or expected earnings of government workers, and the multiple colors denote different types of payment. A legend accompanies the chart to allow for readability of the bars while scrolling downward.
What the bar chart looks like; you can scroll down it for miles! The breakdown of the legend is: dark blue for base pay, orange for permanent bonus pay, green for longevity bonus pay, turquoise for temporary bonus pay, red for overtime, royal blue for lump sum pay, and yellow for other pay and/or adjustments.
As one can see, it’s definitely a lot to take in, but the use of the legend definitely made this dataset a little more easy to understand. Furthermore, the estimates of pay constitute as records within this dataset; data has been arranged and categorized accordingly, such as the payment that applies to pilots, but taken farther by description such as “chief port pilots” and just “port pilots.” Interestingly, chief port pilots make the most pay out of all government jobs; their base pay alone is about $277,000! Another reason why this is a record is that the data set is supposedly counting yearly payment, so information had been researched and noted over a course of time; in this case, from the years of 2011 to 2014.
The dataset’s ontology is similar to what Wallack and Srinivasan described as “a descriptive and classifying system” which negotiate the limitations of two or more groups. The dataset is certainly structured in a sense that allows for any sort of information to be arranged so that it is more user-friendly. The application of a bar chart only highlights the link between each group, such as the types of pay, with the type of job, falling under a total pay amount for the year. I would say that many people would find this data most useful; however, this will absolutely come in handy for those trying to research the city’s top earners and why. Why is it that the top earner is a chief port pilot versus a firefighter? Could it be the different training needed, or employment rates for each job? Such questions like these can be something one may ask when looking for answers using this dataset. It also tells the phenomena of how a job market in a specific area is subject to change over the years. Looking at this dataset, one can tell the demand for a category from another just by pay alone.
What gets left out, however, are additional information that may be even more useful such as how the pay is for part time, or the amount of people they surveyed for one category. Why certain jobs are paid more in bonuses or base pay is also up for question.
If i was starting over with data-collection, I would want to do somewhat of the same ontology that this set has used; charts are just so great in how it visualizes data and maintains organization of it! But I will say that if I were someone else, I would probably look for another way to display the dataset, like a map of where different workers are located that might explain a difference in types of pay, or a little description beside each job that explains what they do. In general, however, the Top Earners dataset on the LA Controller’s Office site is well put together and thought out, and it’s nice to see that a set like this is available for public use.