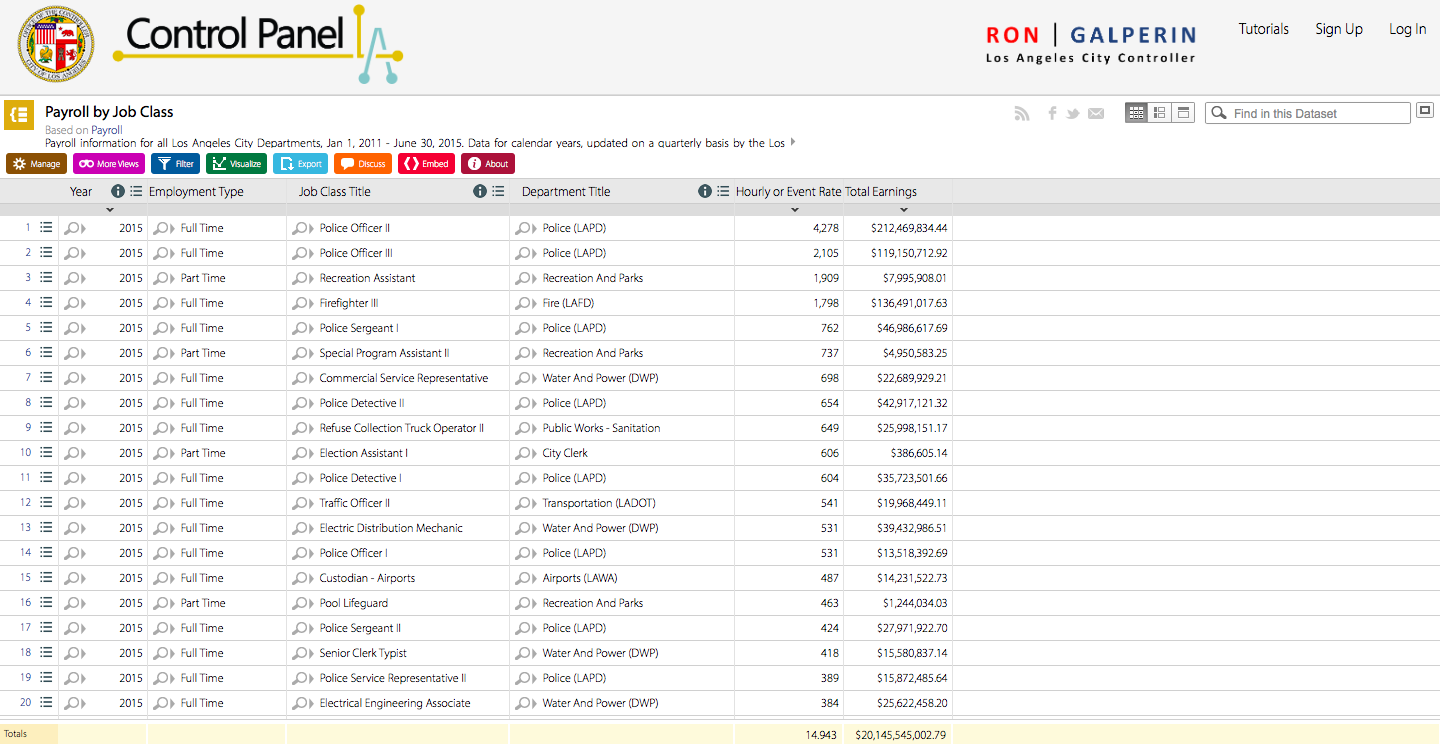
I chose to analyze the Payroll by Job Class dataset on the Los Angeles Controller’s Office Website which offers payroll information for all Los Angeles City Departments from January 1, 2011 – June 30, 2015. The date is organized and inputted into a table format with five content types and hundreds of records to be analyzed. The dataset also offers the option to visually compare the differences in a column, bar, pie, donut or line graph format which is effective when comparing various theories of the amount a specific job class earns. Each record, for the most part, is a different job class title. Each record in the data set has a content type of the year, employment type, job class title, department title, hourly earning and the taxable income for the year.
Wallack’s and Srinivasan’s definition of ontology applies to this dataset because it organizes earnings information about the jobs within the Los Angeles City Departments. This is particularly important and a great asset that this dataset offers because it is a public dataset which is available to any individual seeking potential earnings information. I think this dataset is very useful to the general public because it gives job seekers a chance to analyze the different job fields and earnings potential they may have when entering the task force. This is also useful for individuals who may be in the field of advising college students about their careers because it gives them a better understanding of the job fields that are thriving versus those that are not as popular, which will ultimately benefit their immediate audience or students.
The dataset states that it will provide payroll information about jobs within all Los Angeles City Departments. After analyzing the dataset, one would be able to find that Police Officer II makes the most amount of money from the list. One foreseeable problem with this dataset is that is only offers earnings information without any demographic, gender or educational information about the individuals holding the position. This poses an issue for analytics purposes because it leaves several unknown variables which could prevent a full analysis for research questions.
Although the dataset offers a lot of relevant information, if I were to start-over with the data I would attempt to include demographic information of the individuals holding the positions. For example, gender, race, age, experience and educational degrees would be some data that I would collect and put into the dataset. I feel that this information would be useful for anyone researching more in depth into who actually holds these positions so that the current information could be brought to the attention of the community. This would be great to present to high school students so that they could analyze and see if the specific field matches their interests and potential earnings after high school.