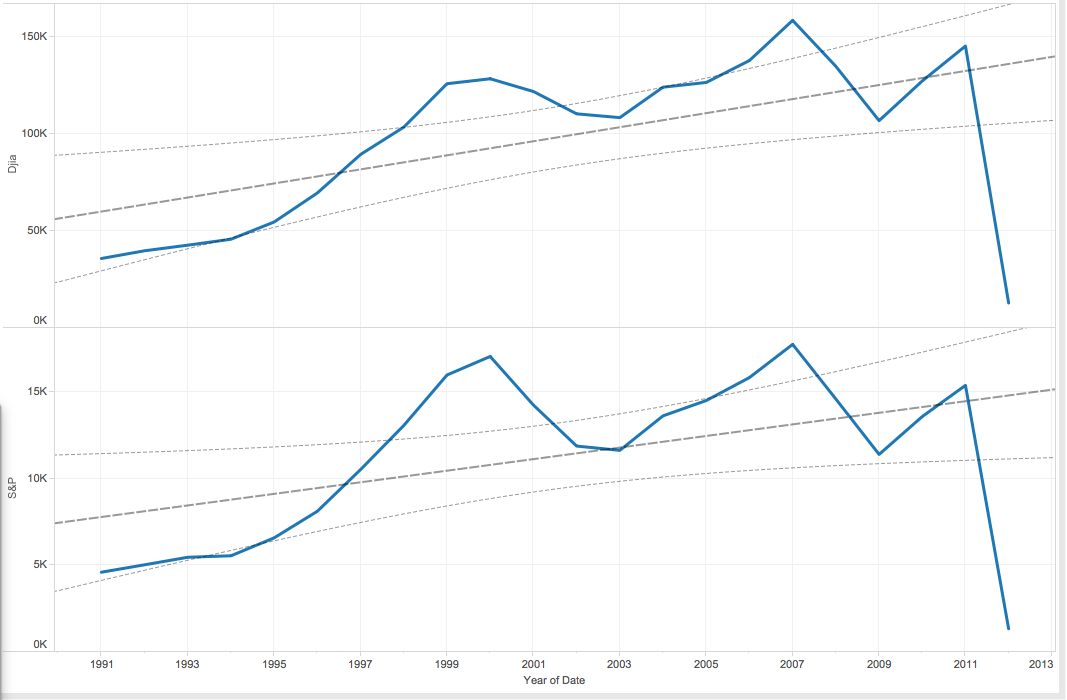
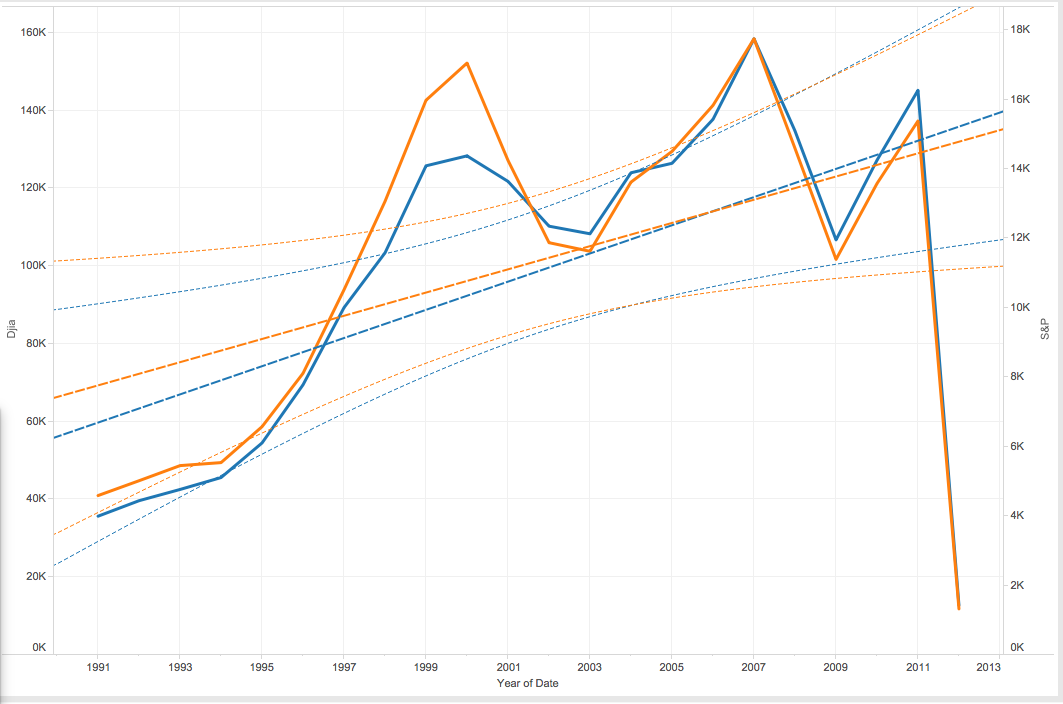
Death Rates and GDP Analysis
For this week’s blog post, I decided to analyze the data and its visualization of the Poverty Statistics. This piece of data informs of the birth and death rates, infant mortality rates, life expectancies, and per capita GNP from 97 countries. With this data, I wanted to focus on the death rates and its association with the country’s GNP. To do this, I used Tableau Public to create two types of data visualizations. More specifically I wanted to analyze these factors in countries that were of interest to me based on living in the U.S. and based on the countries with the greatest death rates.
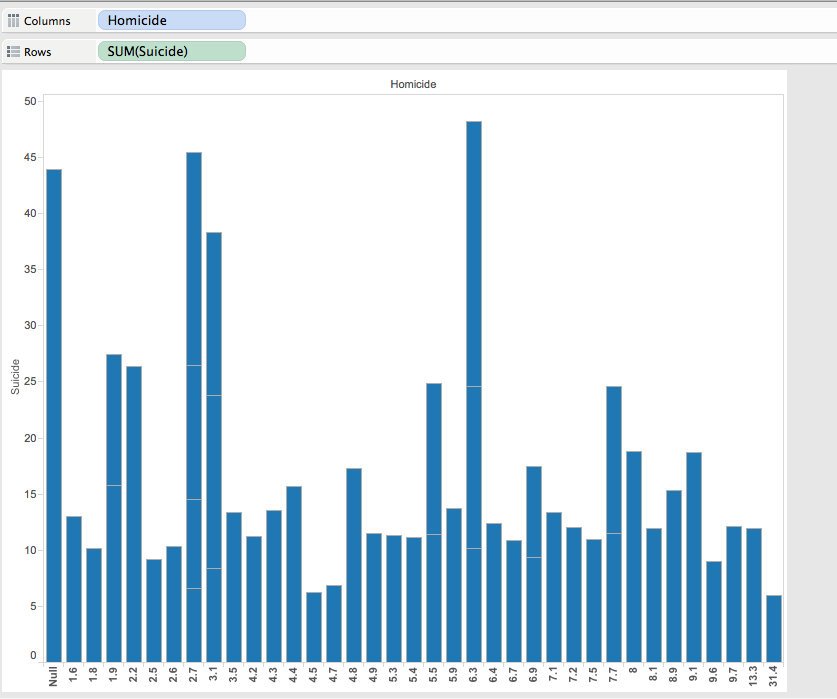
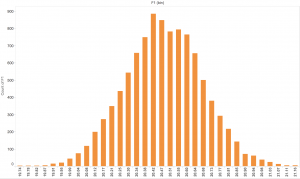
The reason why I chose to focus and use these countries to compare with is because death rates are big indicatives of poverty rates. So for the visualizations on this data, I chose to use side bar graphs to show the death rates of Afghanistan, Angola, Argentina, Bahrain, Greece, Hon Kong, Malawi, Mexico, South Africa, Swaziland, U.S.A., United Arab Emirates, and Venezuela (Image below). Visually, it can be seen that Bahrain and the United Arab Emirates have the lowest death rates, while the one with the highest is Malawi.
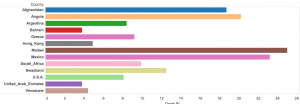
By simply looking at this, we can make assumptions about the socio-economic status of the country as a whole, but we can also infer dietary, and environmental issues. However, since we are speaking of poverty, it is more useful to focus on the monetary values of these countries. For this, I went ahead and produced a table with Tableau that shows the GNP’s for these countries (image below).
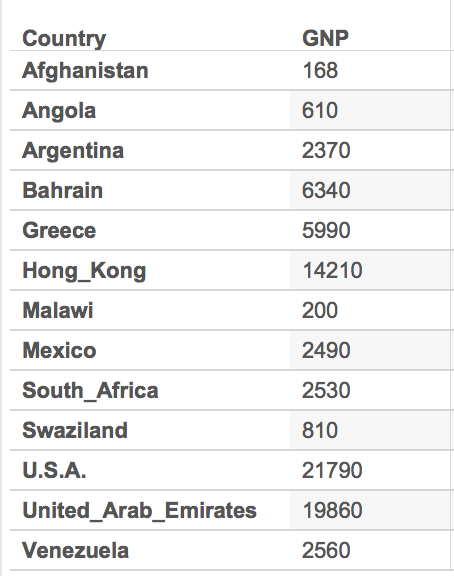
With the table as reference to the death rates, we see that Bahrain and the United Arab Emirates have one of the highest GNP’s up to about 19860. We then compare this to the one with the highest death rate, Malawi, and we see that its GNP falls low at 200. By simply looking at these pieces of data, we can quickly assume that in regards to these countries, there is a connection between the GNP and the death rates which can also be associated with the poverty. However, there is still a lot of research that can be done with just these few selected countries. For example, why is it that Afghanistan has the lowest GNP and a high, but not the highest, death rate? This is just one very obvious observation and question from this small part of the data, but like I said, there is still so much data that can be visualized and studied. Upon studying the countries’ culture we can maybe find out a link between their customs, rituals, diets, or their daily lives.
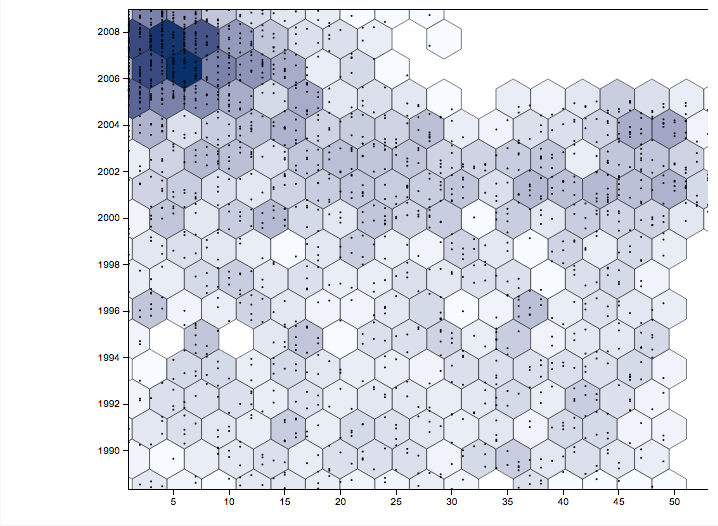
Again, this is only based on a very small extraction of the entire data because it would have been difficult visualizing the entire data set on this small interface as it can be seen below.

-Karla C.