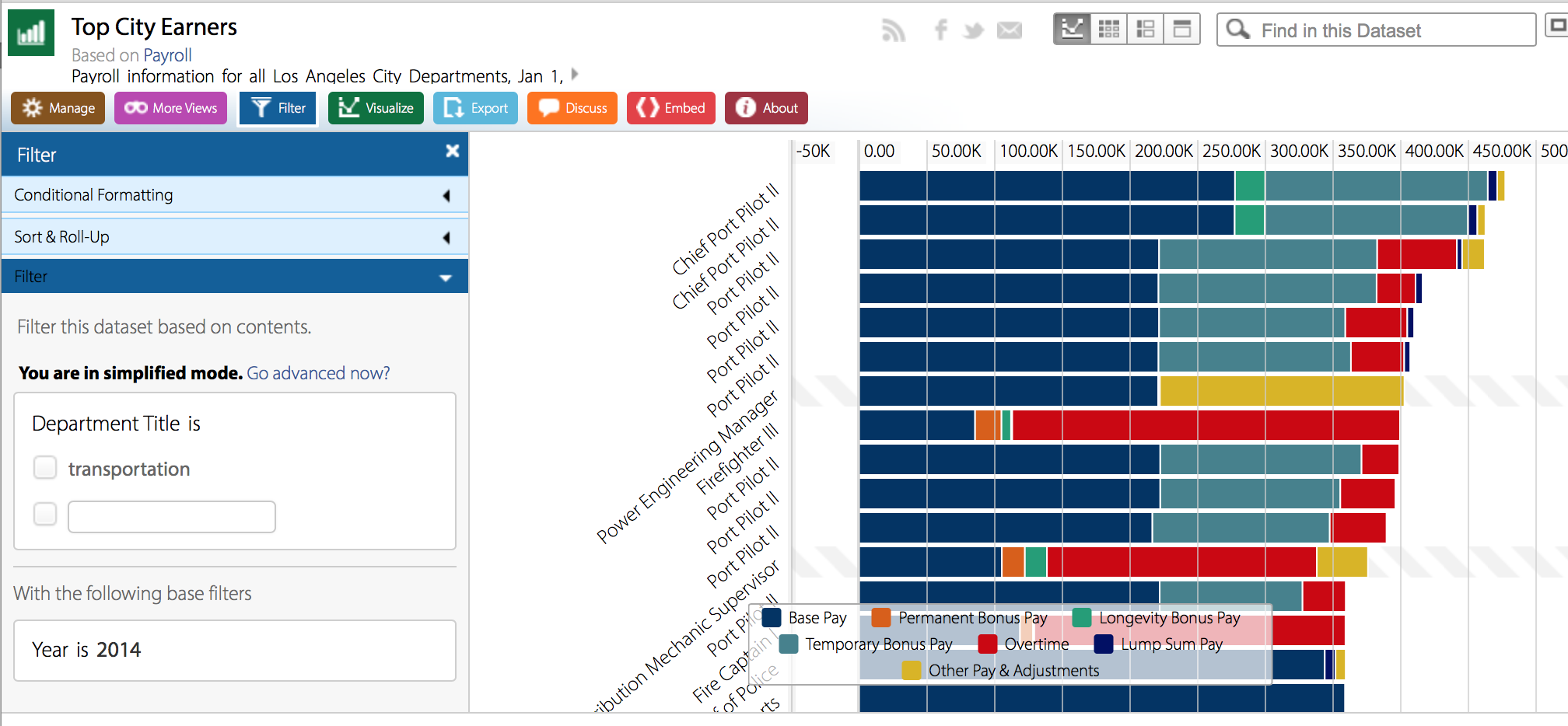
There is an overwhelming number of data visualization solutions out there. I really wish someone could put together a comparison report of a good number of them listing their features, appropriate application, and user critique. In order to learn about the application and make things simple for me, especially during midterms week, I opted to visualize a time series chart of the Dow-Jones Industrial average between 2000 and 2014. This was, however, not an easy task since I still needed to pick the right software application and learn how to use it.
I opted to create my time series chart with Tableau because I believe it is used quite often out there in the “real world,” so it is a good skill to develop. Although it is a relatively simple tool to use, it did take me a bit to learn how to create my first chart. Once you get going become the least bit familiar with it, I really like that through usage you are able to find out what you can and cannot do with the data. Tableau will simply disable charts and options that do not make sense with your data set. Although this may seem logical, it is extremely helpful to analytic neophytes, like myself.
I decided to go beyond a simple time series chart and possibly add a bit more information and a political twist to it. Since we have been learning how charts and data visualizations can be manipulated to show, well, whatever the creator wants to show, I laid out the data points in a discrete (non-continuous) time series chart. On the y-axis I have the Dow-Jones Industrial Average Closing Prices and on the x-axis I the years broken up by financial quarters, which is what the business world uses as a standard to report financial information.
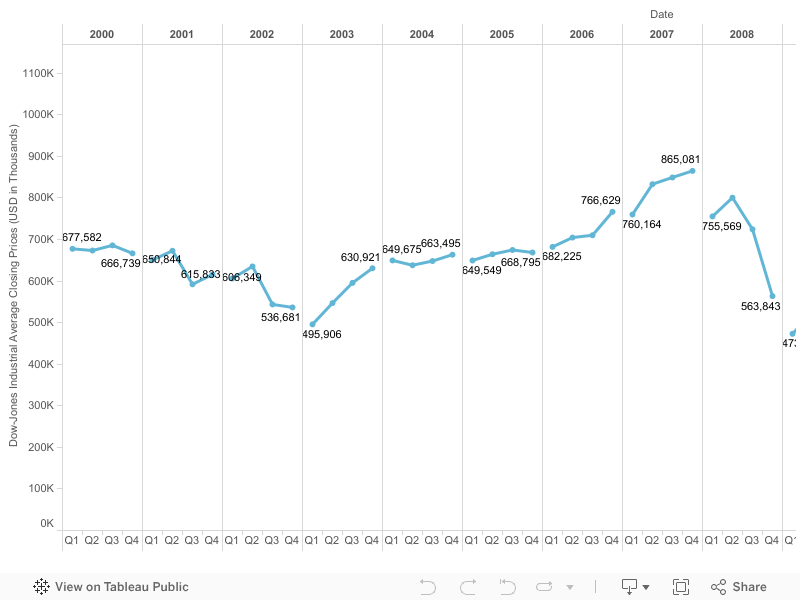
The political twist comes in pointing out that a person can potentially focus on one discrete year and report a trend to their benefit. For example, you had presidential elections in 2000, 2004, 2008, and 2012 within the data. Presidential candidates can point at the prior year’s trend upward or downward and make claims as to the competence of the incumbent in order to rhetorically attack them, while in truth holistic snapshot of the economy between 2000 and 2014 shows an overall upward trend. Furthermore, the time series can be cross-referenced with historic events that may have affected the Dow-Jones Industrial Average.