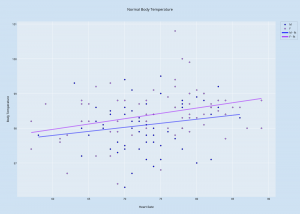
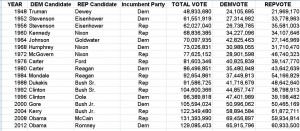
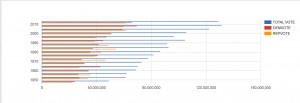
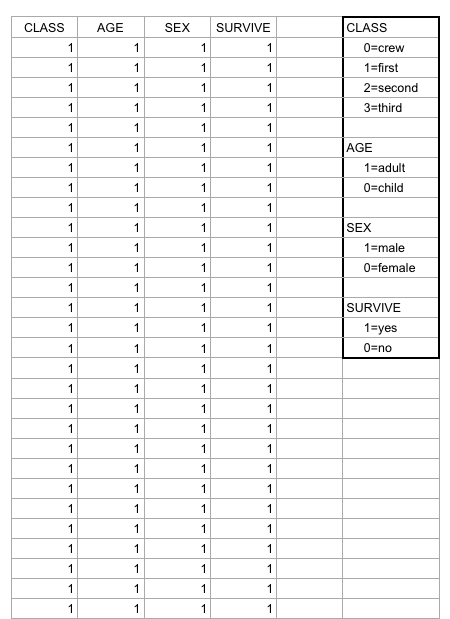
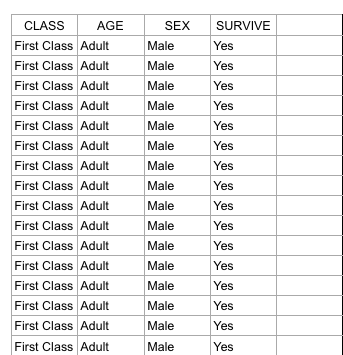
Data set’s provide our societies with valuable pieces of information that helps us understand many things about trends and norms. This information is essential to our survival in a world where things are constantly fluctuating and changing. By analyzing data set’s, our society can understand why things have happened in the past, analyze current trends and predict changes in trends to better prepare for the future. For example, when I first looked at the “Death Data” data set, it was quite overwhelming because of the multiplicity of causes of death around the country. The excel sheet alone does not help me (or any other individual for that matter) understand the data other than being able to view a bunch of numbers that correspond to each state in the United States. However, by using visualization tools to analyze the data and put it into a format that will ultimately help me draw inferences based on the visualization that has been created by a specific software.
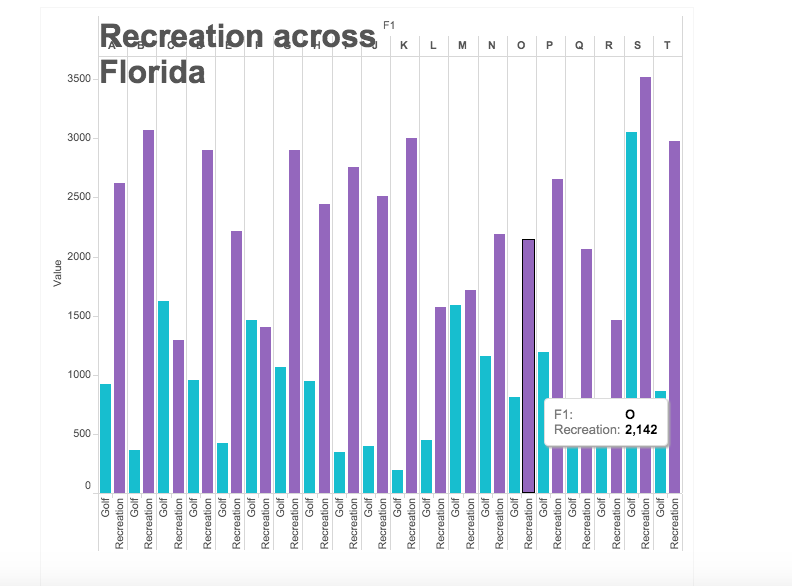
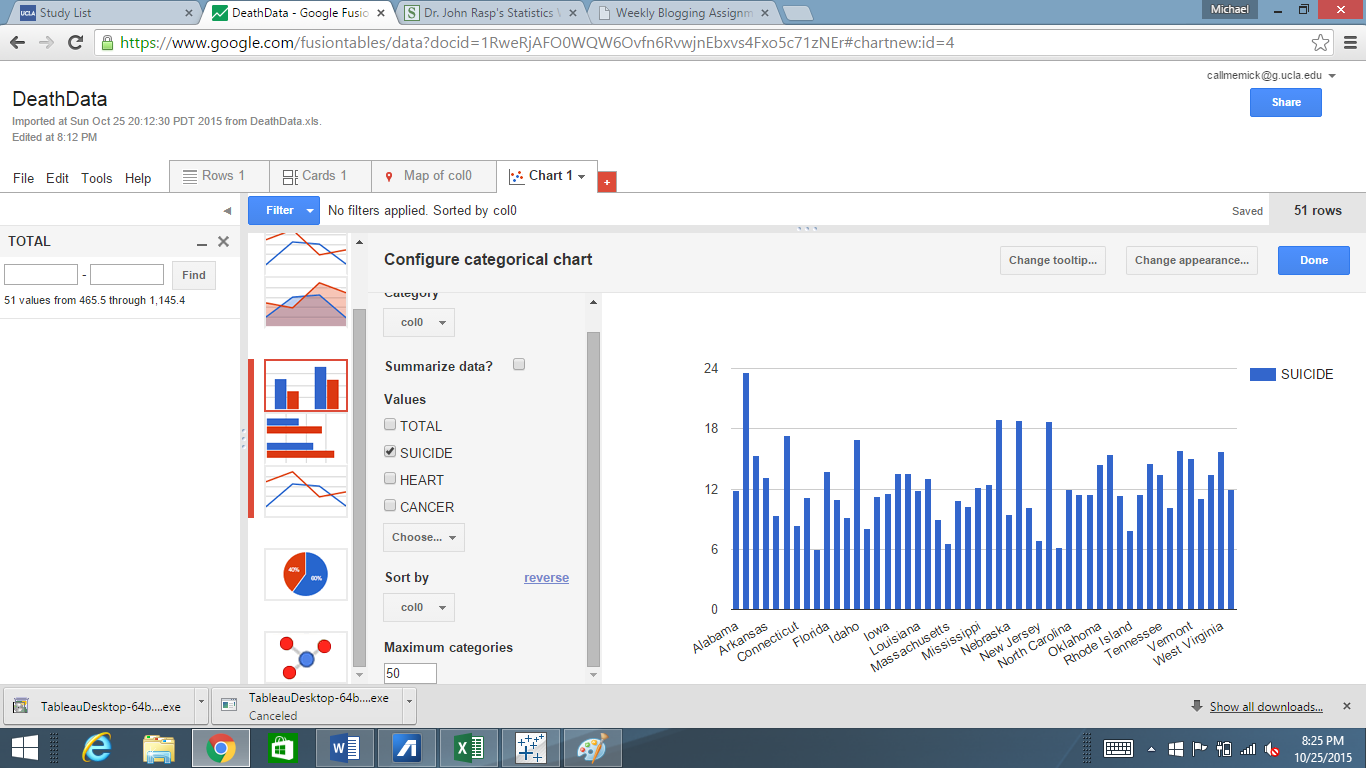
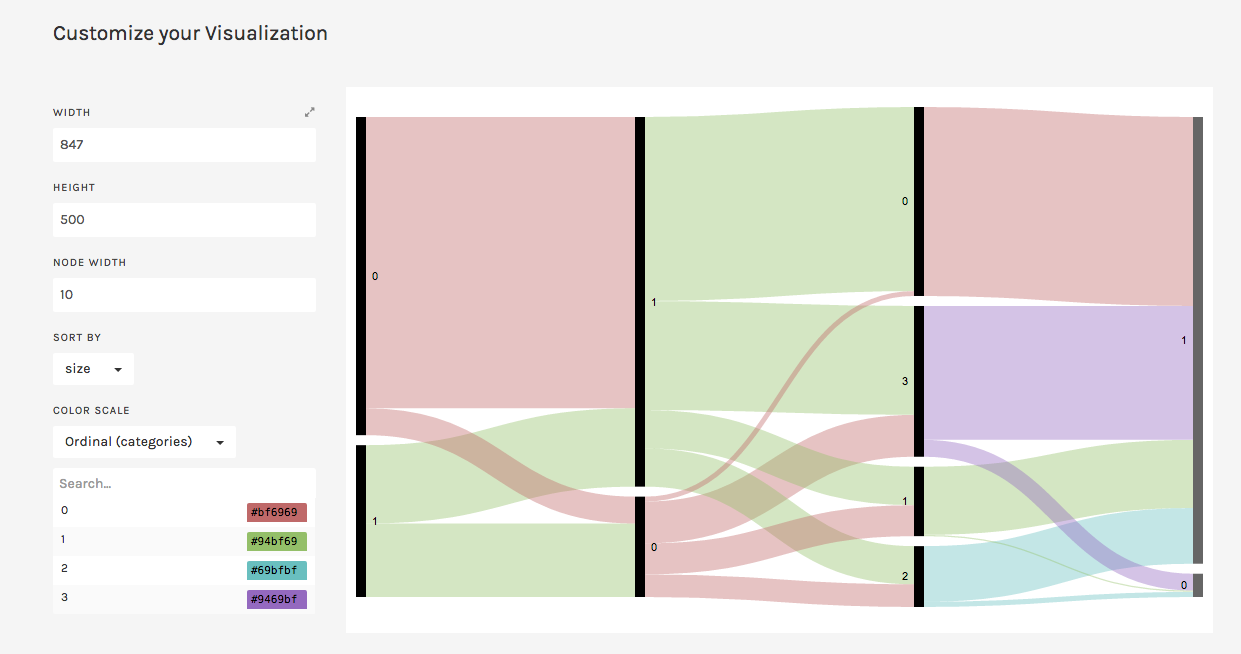
I used Tableau Public to create a visualization of my data set. Since their are so many causes of death, it was difficult to understand the raw data set on the excel sheet. One way to analyze the data, is using a simple side by side bar graph to compare the different states and the various causes of deaths that the data set provided. For example, the picture below depicts the simplest of bar graphs to analyze just a portion of the dataset. In the picture, you can see a comparison, state by state, of the amount of deaths due to suicides in comparison to deaths due to strokes. The visualization allows the viewer to immediately make an inference and conclude that their are more deaths associated with strokes than with suicides without needing to look too much into the raw data itself.
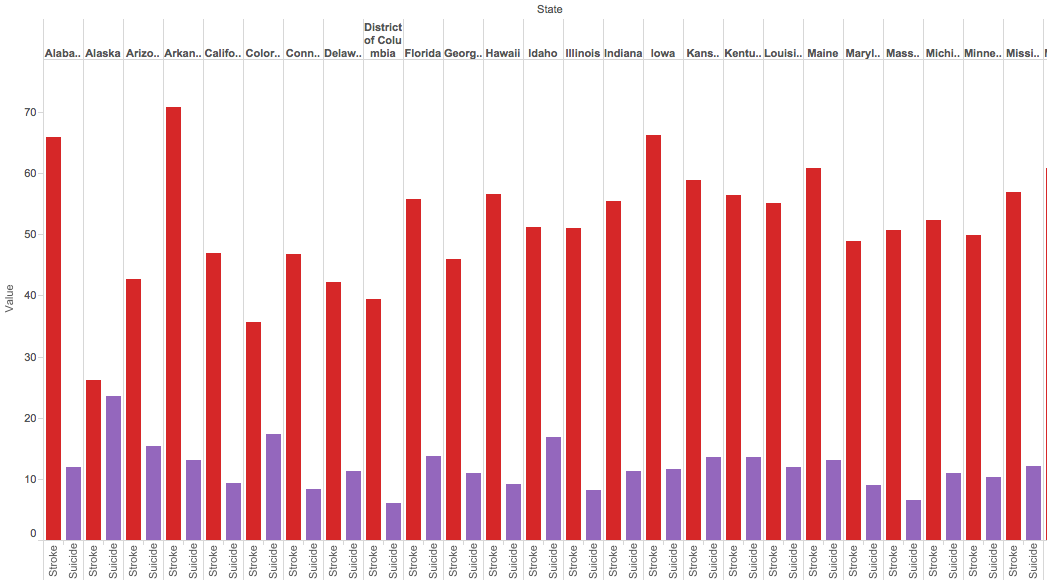
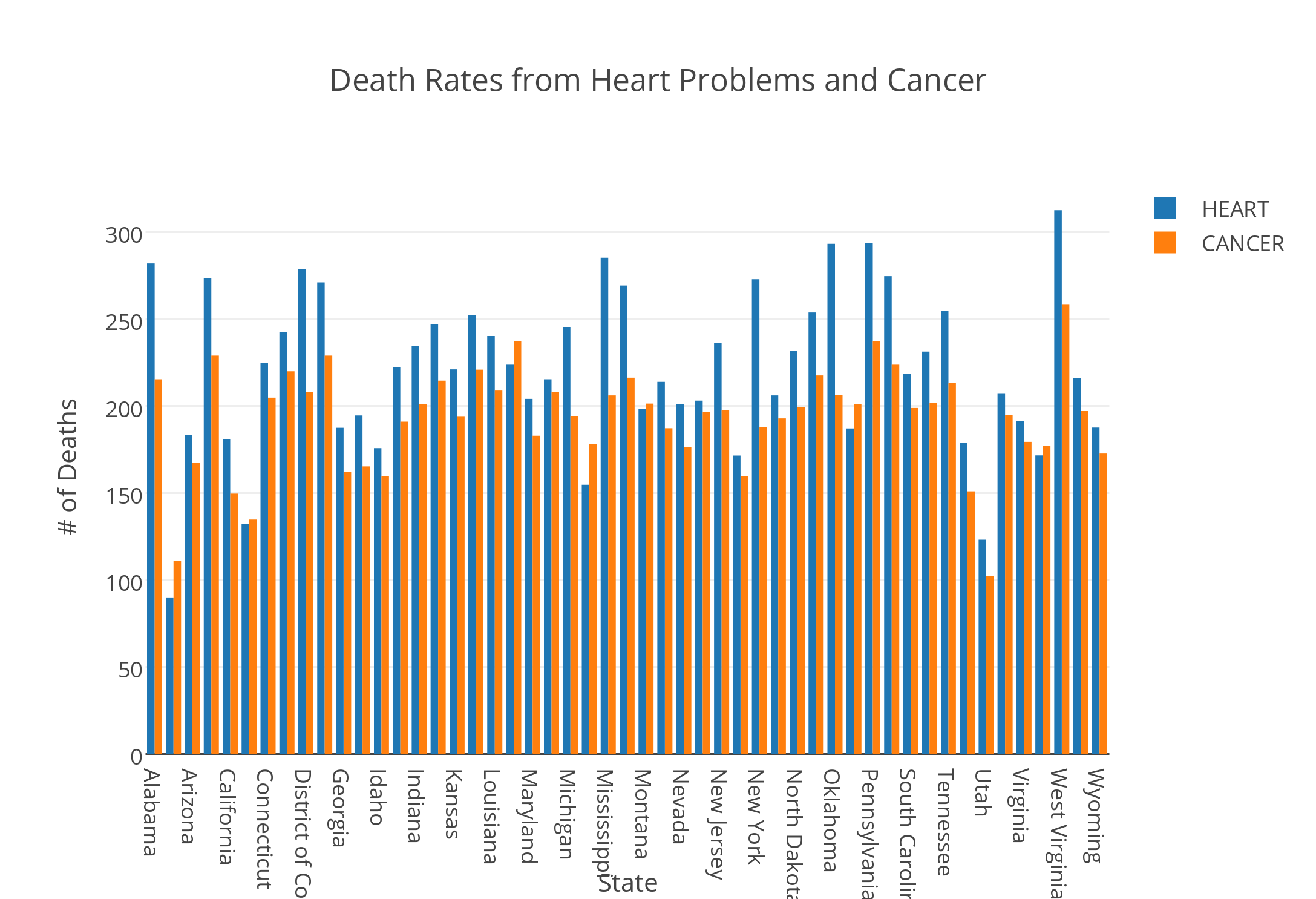
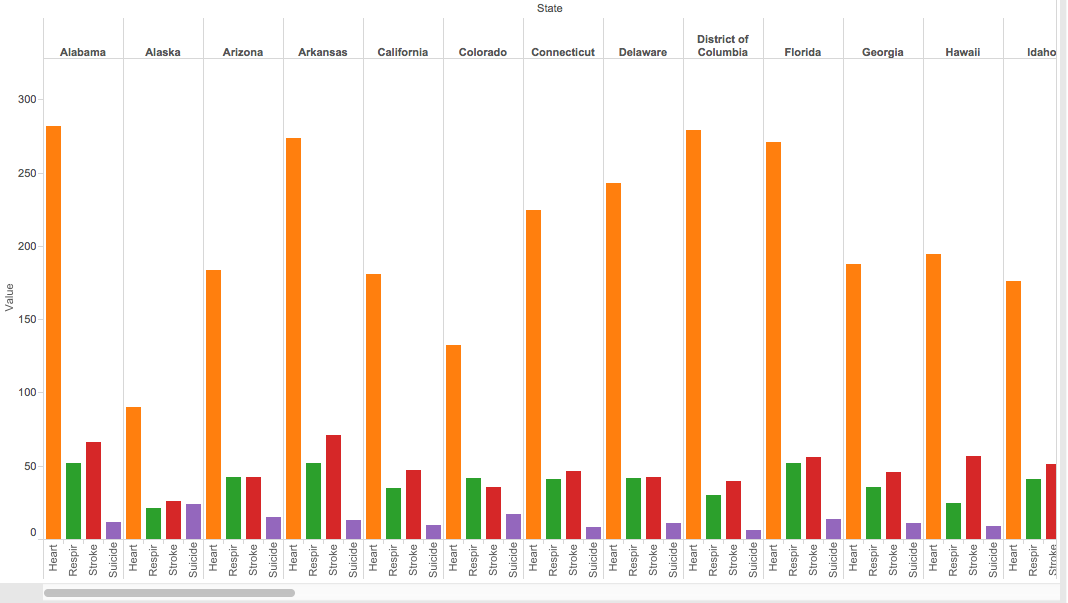
A bar graph can also easily compare more data by simply using various colors to differentiate between the types of categories, in this case types of deaths by state. As you can see in the picture below, the amount of deaths related to heart, respiration, strokes and suicide are easily compared by taking a quick glance at the side by side bar graph; yet, with the raw data from the excel sheet, one would not be able to determine this information as quickly as it is done with the bar graph.
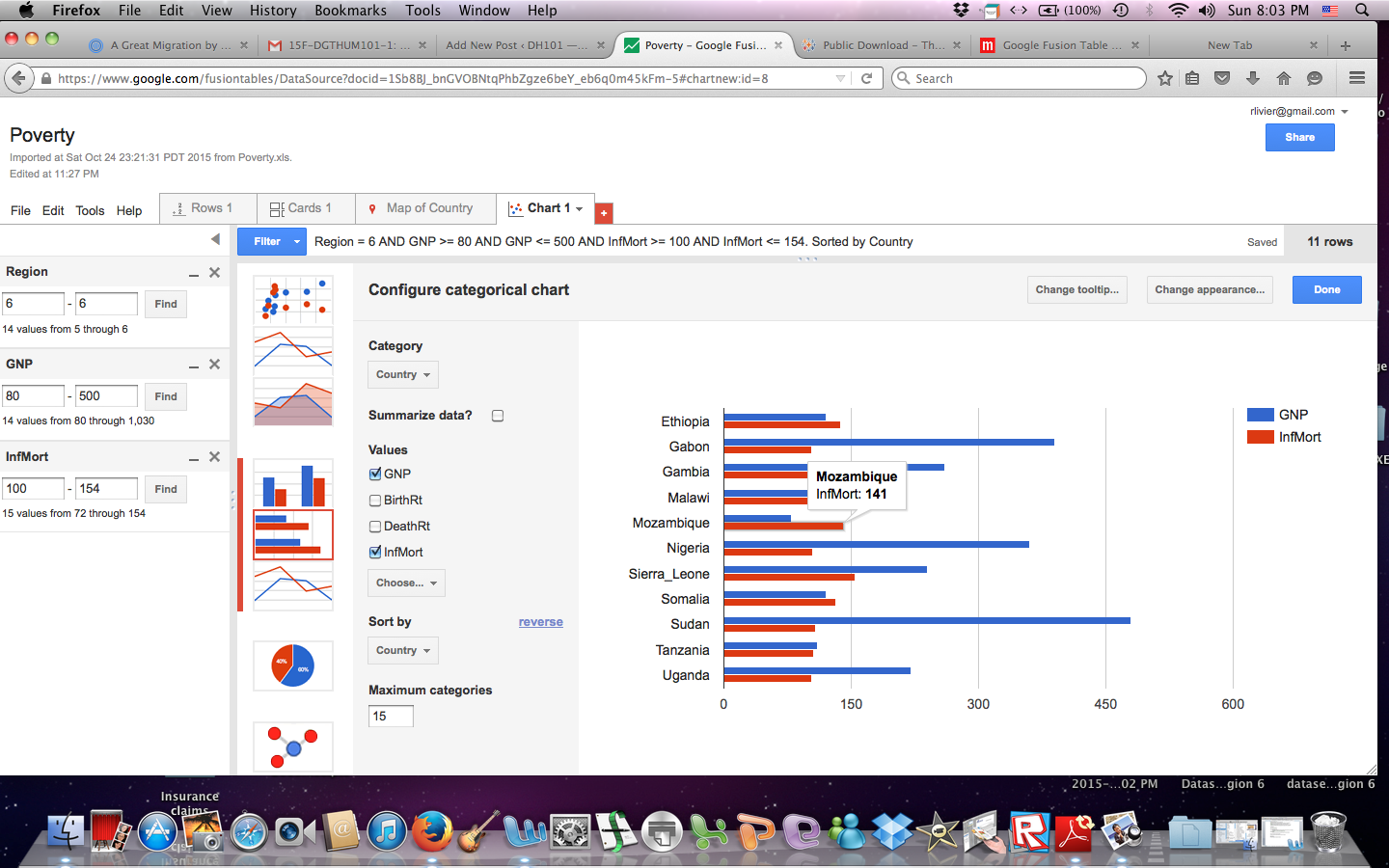
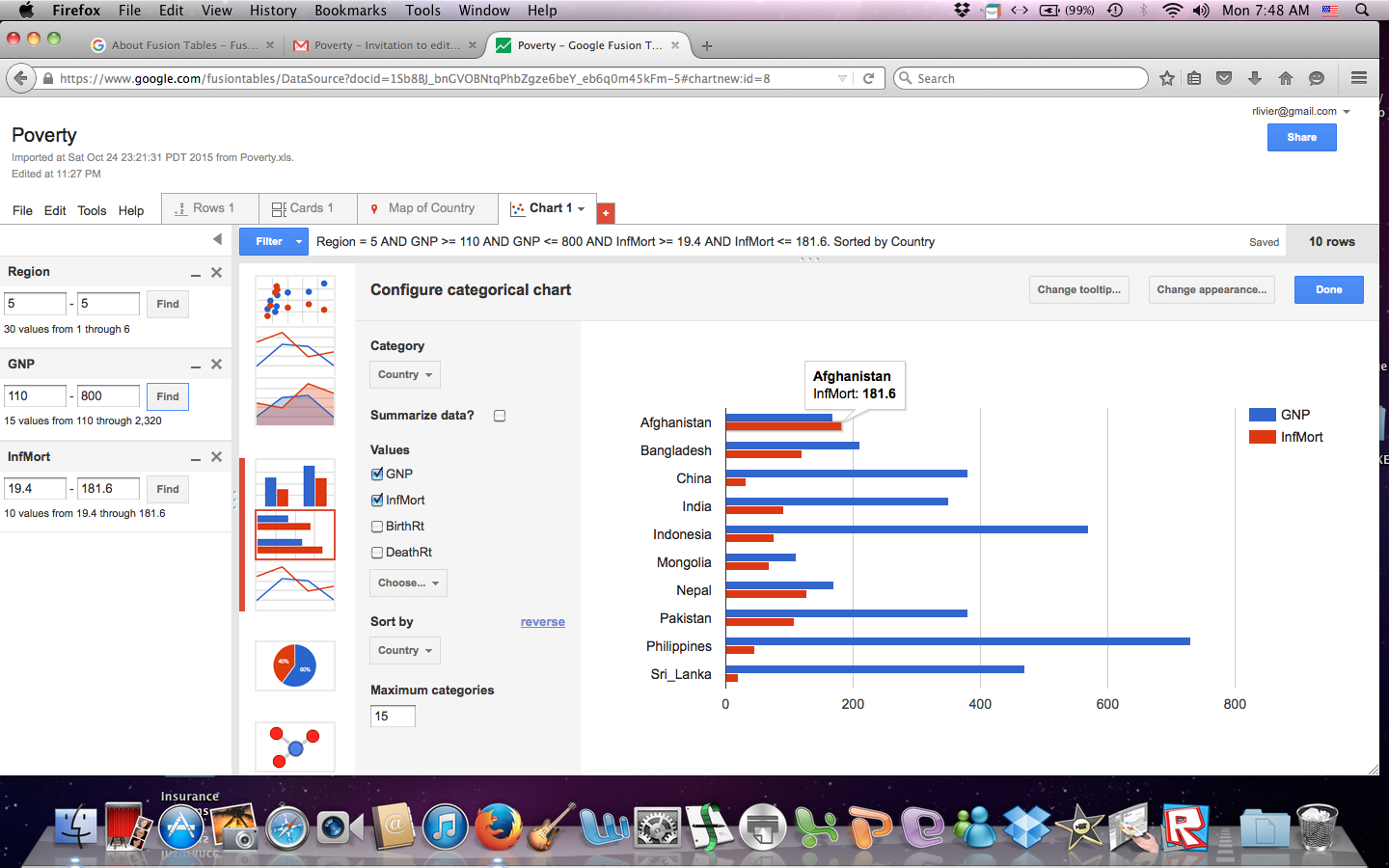
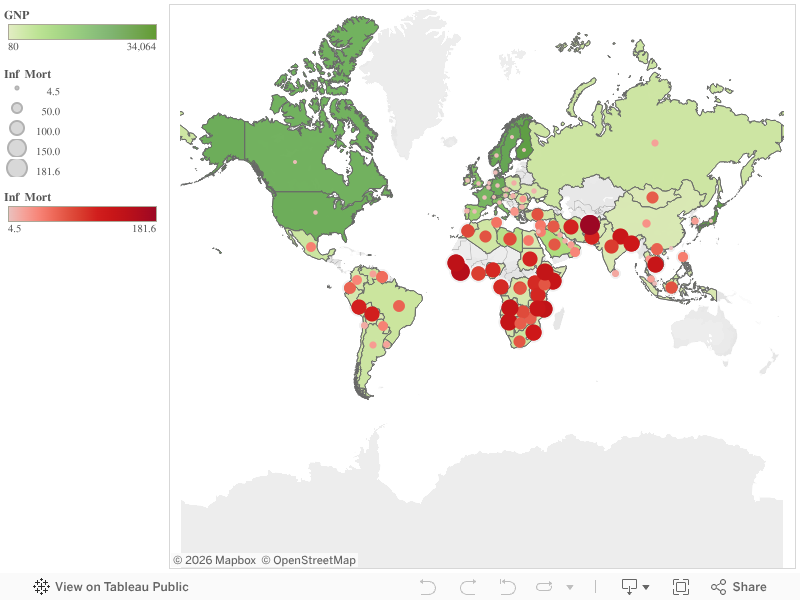
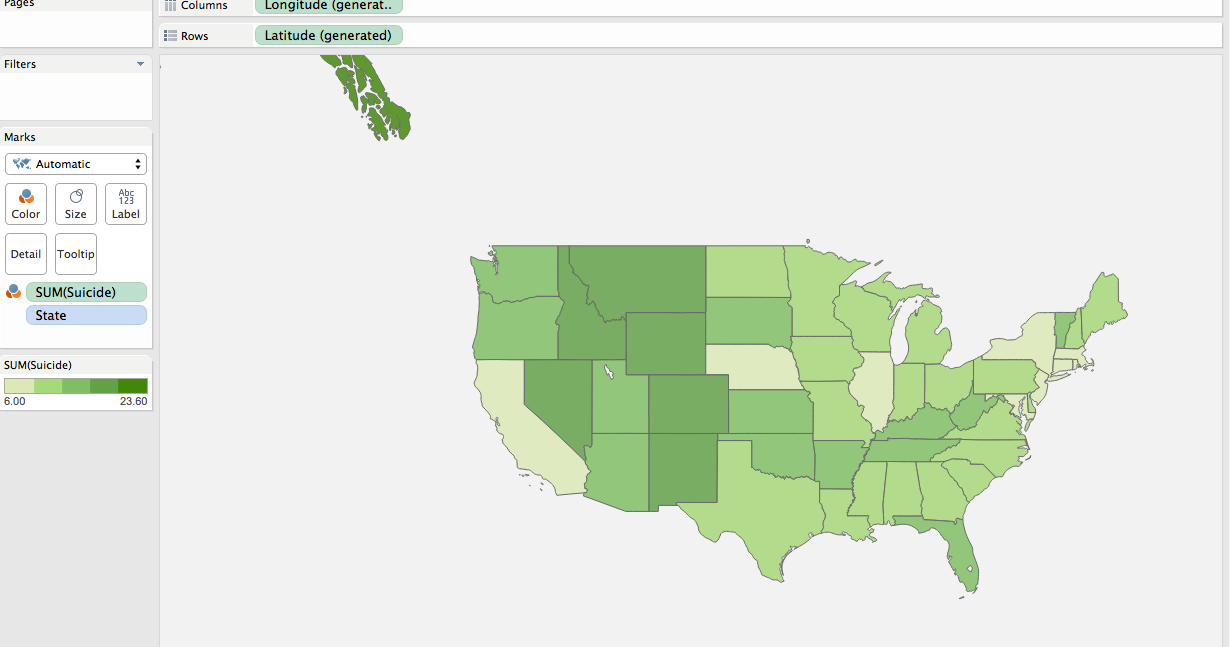
Another way the data can easily be analyzed is by using a filled map to quickly see the potential trends in any part of the world. In the case we’ve been discussing, one can see how predominant suicides have been across the country and where suicide deaths are more prevalent. After quickly looking at the map, you would find that suicide deaths are more predominant in the midwest regions.
Overall, visualization tools are very effective because they help viewers understand data sets in a quick and efficient manner so that analysts can make inferences to help our society.