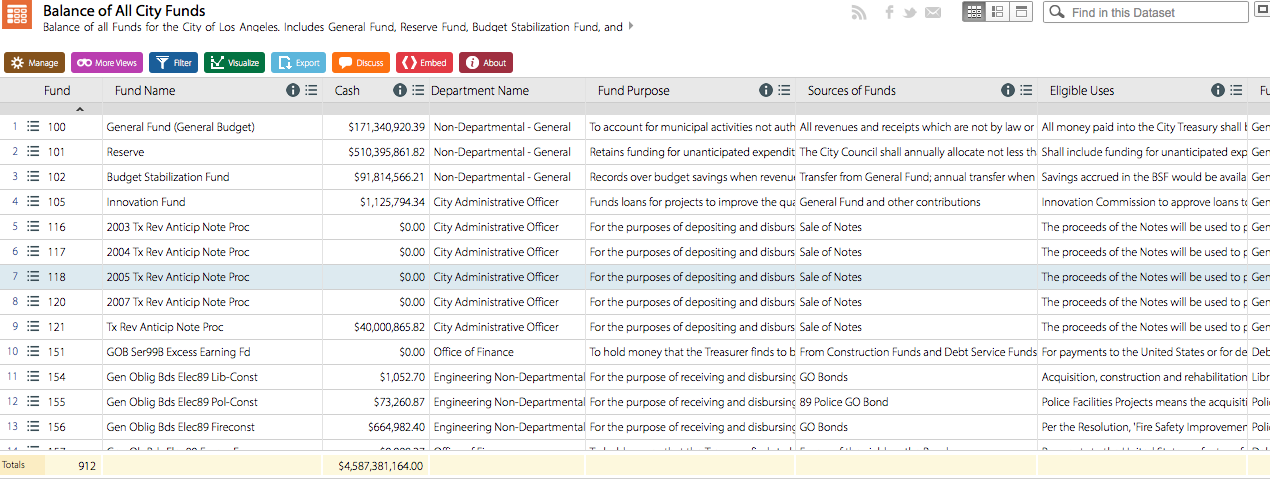
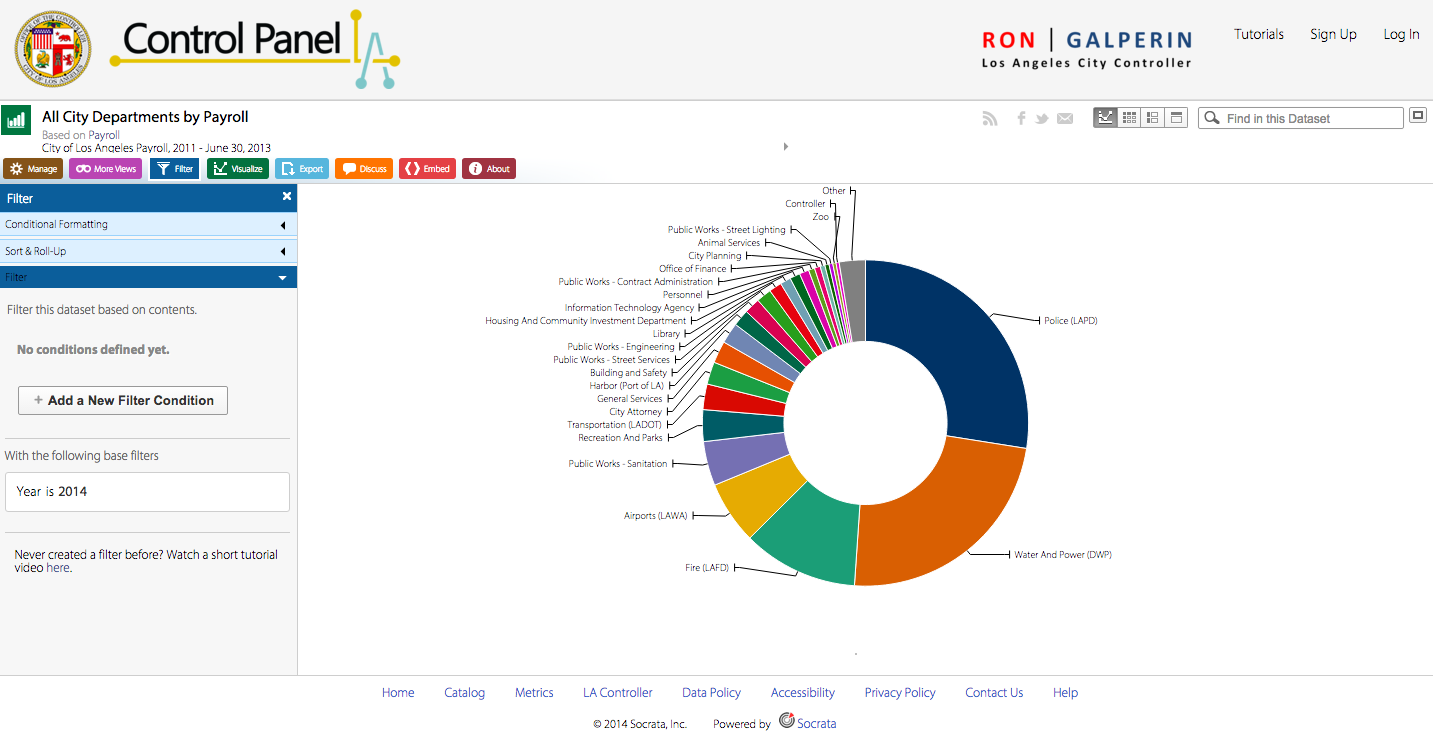
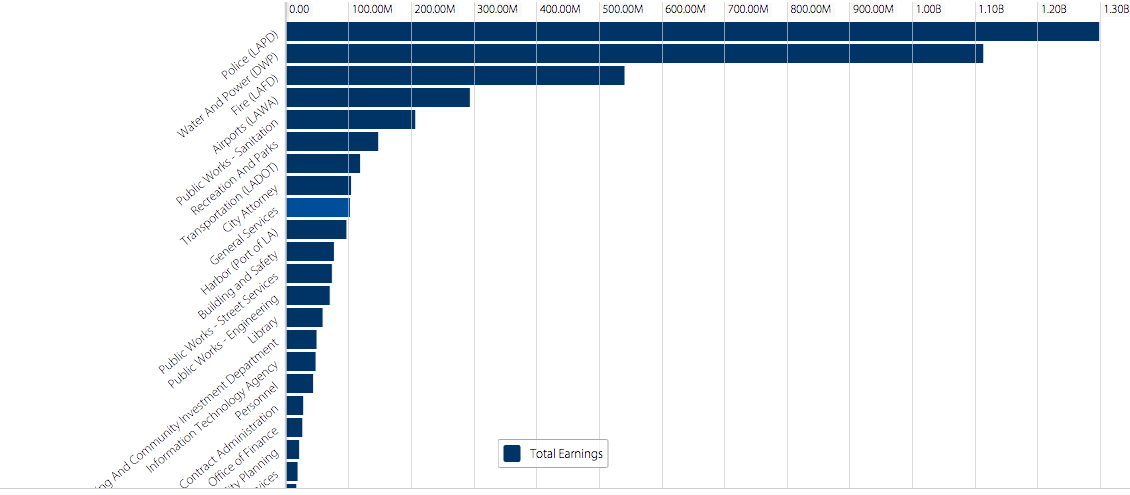
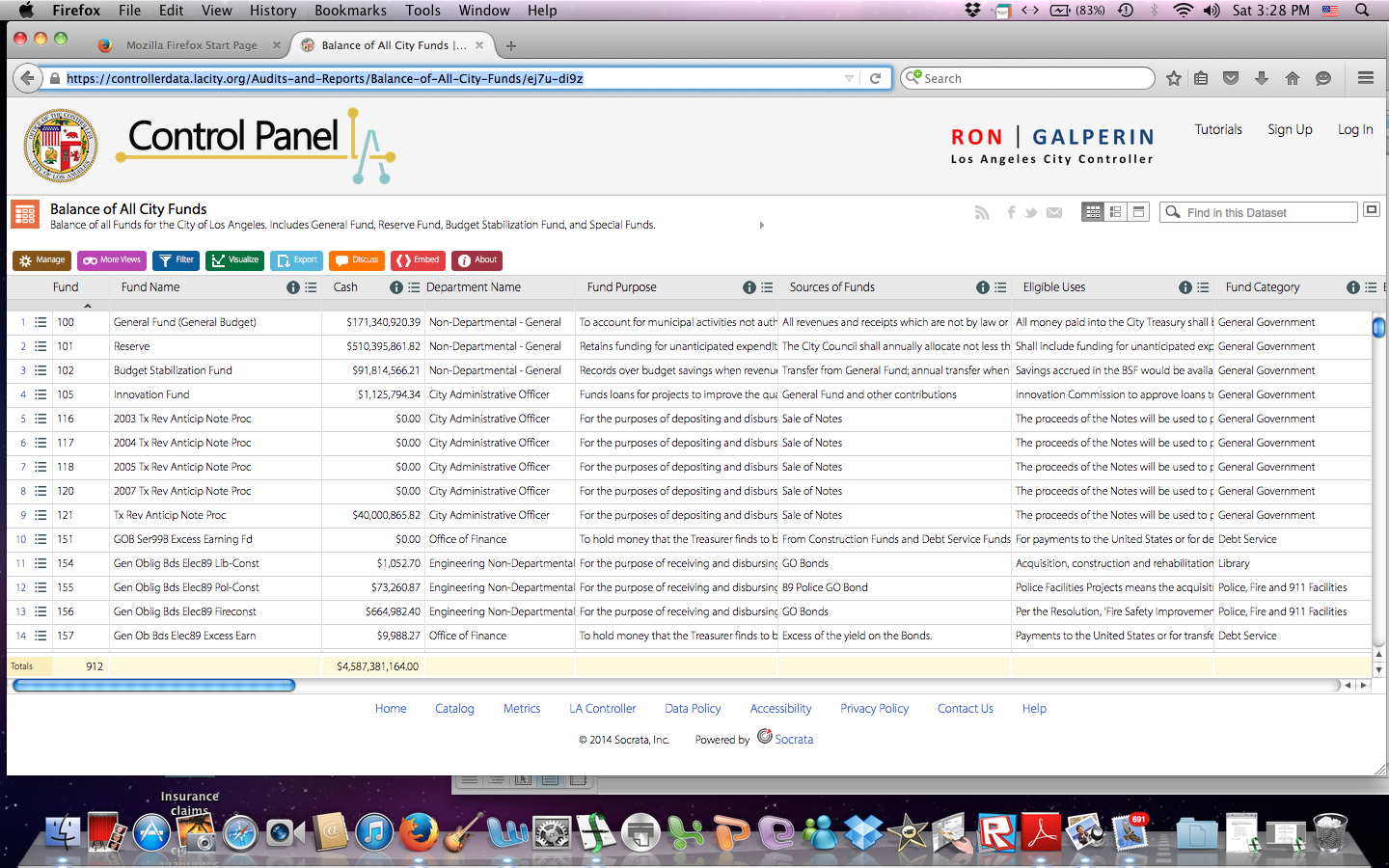
Who would have guessed that Los Angeles top city earners are Chief Port Pilots potentially making over $450K a year according to the Los Angeles City Controller’s office . The data found on this site displays “payroll information for all Los Angeles City Departments” from January 1, 2011 through March 31, 2014. These data were updated on a quarterly basis and contain a very interesting array of jobs and figures. I was very curious to know who is on top of the city’s payroll, which is to say what job title earns the most! Maybe it’s not to late to switch career paths.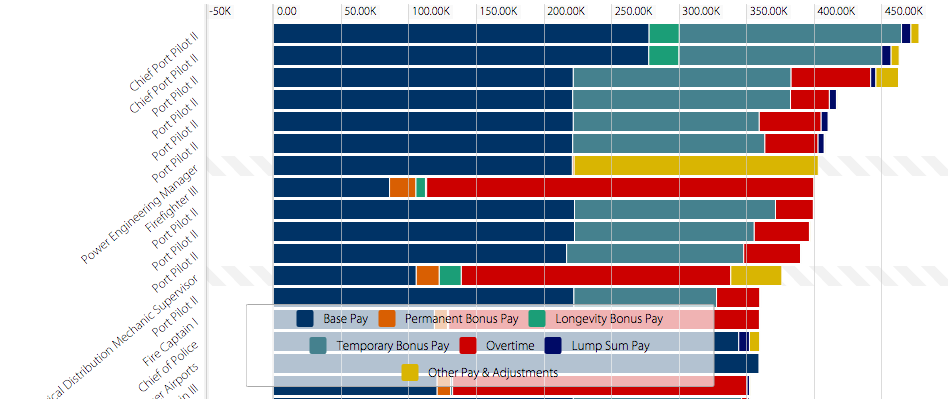
I was also curious to know who is at the bottom of the payroll scale, so I used the sort feature to resort the data in ascending order by total earnings. This provided me with one of the most unexpected results. I received records showing a negative amount. A Planning Assistant, for example, showed negative earnings of more than $30K! Looking at the chart legend more closely one can add that this amount is mostly attributed to “other pay & adjustments.” A an even closer inspection reveals that there is a $150.00 annual earnings amount. I feel like there is missing information because how can someone work to earn only $150 a year and owe more than $30,000? There is more to the data than is visualized here. 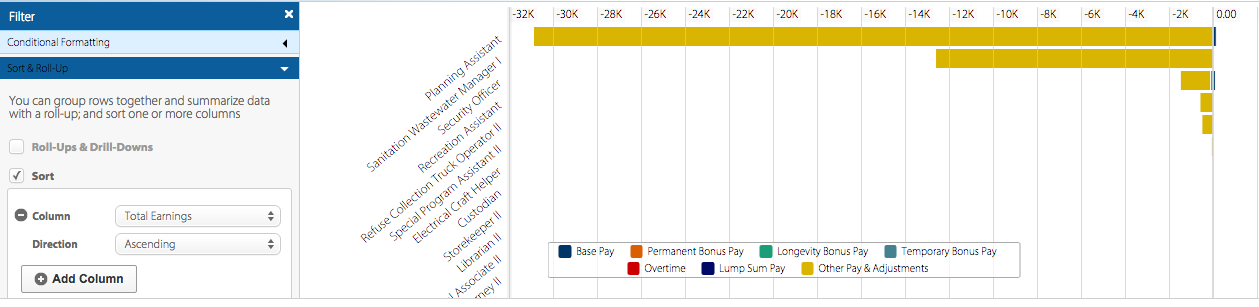
Pardoning the potential outliers, I really like that the system is intuitive enough to use quickly. I also appreciate its power and flexibility enabling users to “slice and dice” the data. For example, some of the available data types related to earnings that a user can sort through, filter, and compare include Base Pay, Permanent Bonus Pay, Longevity Bonus Pay, Temporary Bonus Pay, Overtime, Lump Sum Pay, and Other Pay and Adjustments. Other data types include Year (of earnings), Department Title, Job Class Title, Pay Grade, Employment Type and more.
The system’s power derives from the flexibility to quickly change criteria to sort by and the visualizations from graphs, to tables, to list view and grid views all while maintaining the criteria you had selected. There is a “discussion” functionality that enables users with the ability to write comments, you can embed HTML, and even save and export your data to a good number of popular formats. The cherry on top of is that you can share any dataset on social media. What more do you want? Well…actually a lot more…
As powerful as this system seems to present quantitative data, it lacks in providing human data or contextual data. I began to play with the tool by looking at the top and bottom earners. Although I was able to successfully find them, it raised more questions because of the lack of context. Why does a Chief Port Pilot II make the most? I could not find data type that could point to the answer. Looking at the top earner or record in the dataset in itself may not be enough to answer the question. I can however, say a few things about this particular record. Although the total earnings in this record list a total of more than $450K, we can break it down to what type of pay contribute to that sum. According to the record, a Chief Port Pilot II makes a base pay of $258,096.00, a longevity bonus pay of $22,354.64, a temporary bonus pay of $164,429.12, a lump sum pay of $6,947.05 and an adjustment pay of $5,954.00. This provides us with a sense that a Chief Port Pilot II needs to perform or somehow maintain a level of work in order to achieve the $450K earnings mark.
According to Wallack’s and Srinivasan’s ontologies there are mental models that encompass a system of categories that a particular group of people uses in order to experience and make sense of their world or reality. These categories dictate how they term, phrase, and interpret their experiences. In other words, there is a set of data types that are featured in the Top Earners data set that make up the ontology of the group that created the database: The Los Angeles City Controller’s Office. They are most concerned with the data and it was collected and organized from their point of view. In Wallack’s and Srinivasan’s parlance this could be considered the “state-ontology” as it seems to be a “state-created information system” that reflects the earnings of possibly a large number of “local communities” (Wallack’s and Srinivasan’s 2009:1). These local communities may have a completely different ontology that does not feature the data types listed in this data set, but that may provide context and meaning to these data. In anthropology this is the difference between an etic (state-ontology) and an emic (local-ontology) perspective.
On the surface the dataset does provide a very quick glance at the top city earners in the Los Angeles area. You can see very quickly that the maritime commercial industry–one of the local communities represented in the dataset–is very lucrative, but it does not tell you why. The context and “local communities’ representation of their contexts” is left out. Further investigation on the Internet may provide a mental map or model that sheds light on the experiences and ontology of these top earners, namely the Port Pilots. For example, according to a Bloomberg article written in 2011, the Port Pilots that were interviewed feel that they “perform an important function and [they] do it safely” (Palmeri and Yap 2011). Furthermore, if we take in account the risk of a tanker such as the Exxon Valdez type vessel potentially spilling oil costing billions of dollars to clean up, we start forming a picture or setting a frame of reference that provides us with perspective and possibly understanding as to why they are paid over $400,000 a year. These Port Pilots need to be extremely well trained, have “years of experience and detailed knowledge of the harbor, working in dangerous conditions,” and be held accountable for anything that goes wrong. Finally, the value comes into perspective when they, the Port Pilots, state that “there’s 7 billion people in the world and less than 10,000 who do this” (Palmeri and Yap 2011).
From a Port Pilots perspective and his community of maritime experts as well as the people that depend on their skill for their lives (not to mention the environment), there are quite a few data types missing in the dataset that provide context of their work. With out this context one can quickly draw the wrong conclusions. One can even be tempted to be upset at the fact that Port Pilots make so much money and wonder if the tax payer is responsible for the bill. By the way, according to Bloomberg the tax payer is not paying their wages. From the Port Pilot’s point of view, I can imagine them wanting to include at least the following to the ontology: years of experience, locations of experience, who is paying them, risk level, exposure level, experience rating, training, education, largest vessel maneuvered, average vessel maneuvered, number of berthing operations, number of unberthing operations, and things related to their mental model of their job experience.
BIG DATA a is a term that refers to a large quantity of (sometimes complex) information, typically quantitative, and often times failing to provide a “thick description” of phenomena (Geertz). Furthermore providing insight and matching state and local ontologies is probably another frequent failure. We are coming up on technological capabilities and models that are beginning to provide a contextual and digestible “thick description” out of big data. What this means in this particular dataset is that the state-ontology and local Port Pilot communities’ ontology will be able to someday leverage the same datasets without having to learn each others ontologies thereby making the data represented richer, more relevant and meaningful.