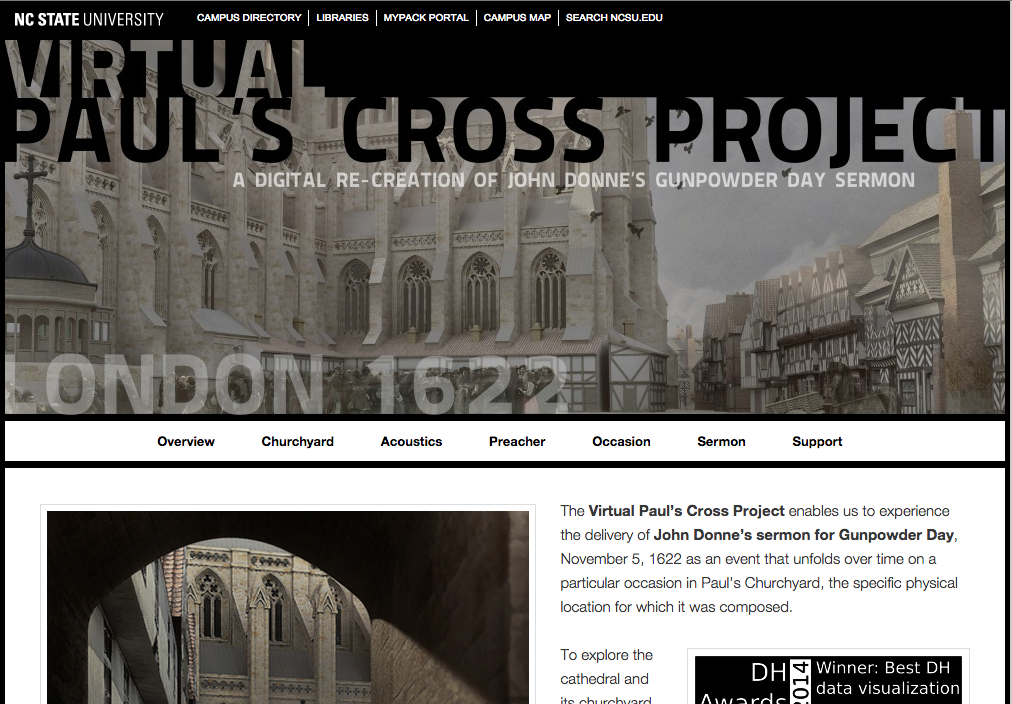
This week I explored the Salem Witch Trials Documentary Archive and Transcription Project. The website essentially serves as an archival collection for thousands of documents and transcripts (including court records, record books, letters, sermons, diaries, maps, etc) that were created during the Salem Witch Trials. The website has ultimately compiled a large amount of documents from the Salem Witch Trials; transcribed the documents from paper (or parchment) into a digitized form, and provided commentary on the various documents contained within the website.
One of the biggest sources contained on the website are the various documents that were compiled from various libraries, including documents from the Boston Public Library. One of the most interesting sources that the website contains are the documents related to the accusations of witches. Further, specific maps of Salem have also been compiled and put into pdf formats which are available to be downloaded onto the users computer. The text analysis also serves as a great source since the individual who headed the project, Benjamin C. Ray, has actually thoroughly studied the religious influences that surrounded the Salem Witch Trials.
The sources were processed onto this website using a number of methods, including being organized, enhanced, digitized, and photographed. since so many sources are contained on the website, the creators organized them into the following categories: documents and transcriptions, historical maps, archival collections, and contemporary books. The document section includes court records, record books, personal letters, sermons, diaries, etc. The historical maps section includes a number of detailed maps of Sale in 1962, maps of the districts were the most accusations of witches were occurring, maps of Andover, etc. The archival collection provides a searchable database with notable individuals, such as court officials and pastors, during the Salem Witch Trials.
The website was overall presented in an okay manner. For the most part, the website lacks interactivity with the user, especially since it lacks a more visually appealing approach. Also, the website is not that user friendly because the link on the website are very slow and oftentimes do not properly load. The maps provided are, although detailed, basic in the sense that they are not interactive. One way to fix this would be to make the maps 3-D. One positive outlook on the website is that it is very well organized and easy to find specific sources because of the way the categories have been created.
Overall, the website does a great job of organizing the sources for the project although it lacks interactivity with the users of the website.



 and even his perceived
and even his perceived