The Gender Breakdown of City Workers by Department is a dataset that has been released to the public from the L.A. Controller’s Office. More specifically, the dataset is an analysis of 2013 full-time employee earnings by gender across the various departments of the City of Los Angeles. Presented initially as a table, the site gives you other visualization options for the data, such as a bar chart, line chart, or pie chart.
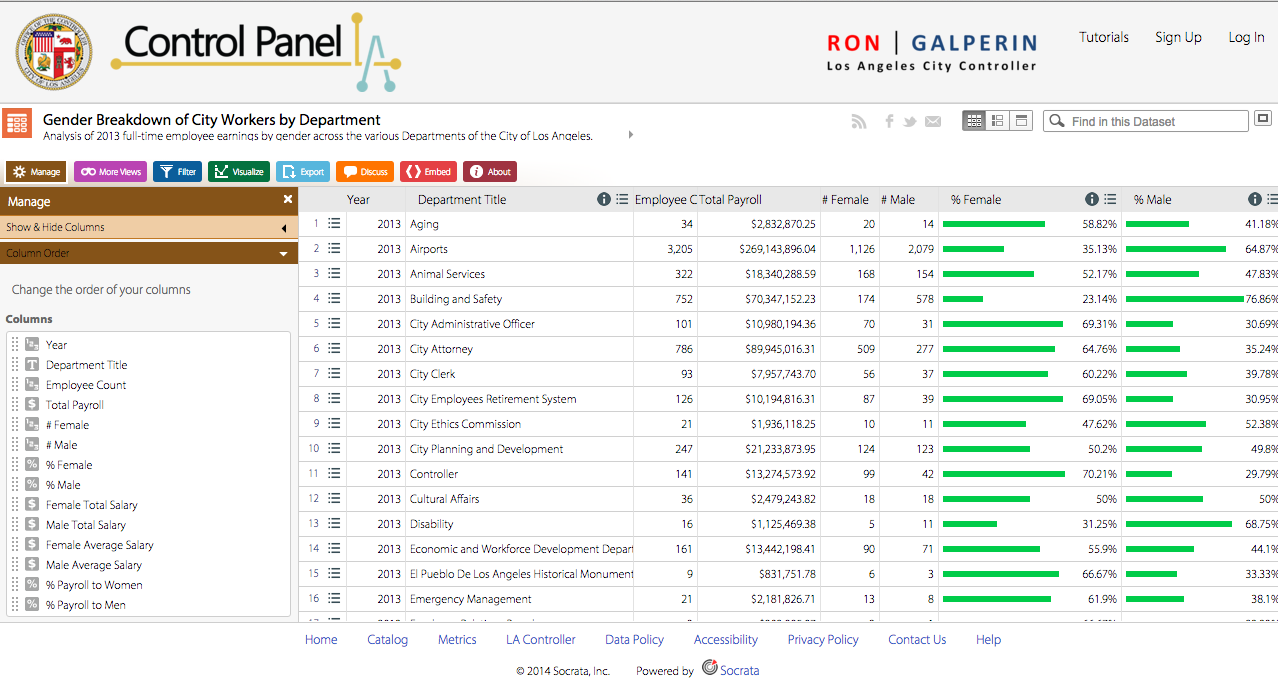
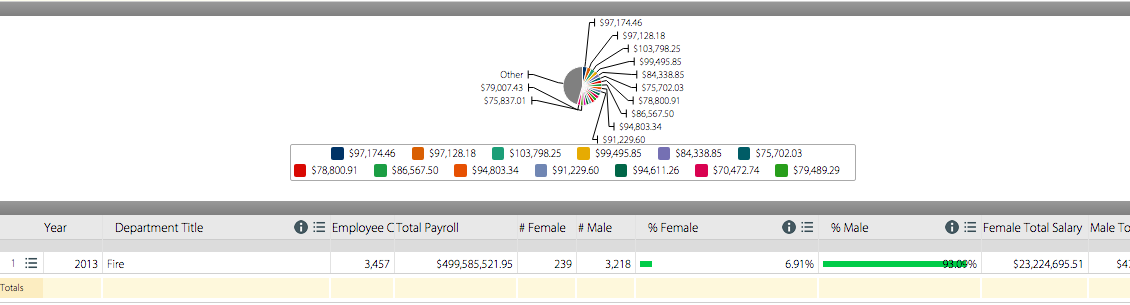
Its data/content types include: year, department title, employee count, total payroll, number of females and number of males (in each department), the percentage of females and males, female total salary, male total salary, female average salary, male average salary, percentage of payroll to females, and percentage of payroll to males. This dataset has 41 rows, or 41 records. What constitute a record in this dataset is a particular City of LA department and its individual values for each relevant data type corresponding to that specific department.
Wallack and Srinivasan define ontologies as “systems of categories and their interrelations by which groups order and manage information about the people, places, things, and events around them” (2009: 1). In other words, ontology is the term that represents the way in which real-world matters are labeled, categorized and interpreted. This particular dataset’s ontology can be identified under multiple categories, such as economic (payroll) or more social (gender). This data has also been categorized by the LA Controller’s Office itself, as it’s been tagged under such categories as “equality”, “employees”, “demographic”, “women”, “wage gap” and more.
Those who would find this dataset the most illuminating would probably be activists for women’s rights, policymakers, and academics focusing on gender studies. More specifically, people who are interested in researching discrimination in the work place and discrimination amongst different genders. This dataset could be used as hard, statistical evidence in the fight against the wage gap, the glass ceiling, and inequality in general.
In reference to the year 2013, this particular dataset shows that female employees working in a number of departments in the City of LA earned a lower average salary than their male peers in their respective workplaces. For example, in the Department of Cultural Affairs, females had an average salary of $58,563.10 while males had an average salary of $79,172.67—a difference of a little over $20,000. Most of the records in this data set fall under this description, with females earning less then men in a high number of departments. In addition, in workplaces where females have earned a higher average salary than males, the difference is small when compared to the gap when males have higher wages than females. The dataset also shows the number of females to males in the departments, which also can have a large difference in count. This dataset definitely tells a lot about the controversial phenomenon of the wage gap between gender in this country, which exposes a type of discrimination that is still in effect in governmental departments in such an influential and progressive city as Los Angeles.
Even though the dataset is fairly complete in payroll statistics amongst females and males, there are a few data types that have been left out. For example, ages of the workers might add more valuable information to this dataset. Perhaps, seniority level/years on the job and education level of the employees would help illuminate the issue, as well.
If I were to re-do this dataset and start the data-collection all over, I would focus the ontology on age/seniority level and relevant education/experience. My data/content types would probably include age, position, number of years employed in the department, salary, and education level/relevant job experience. I would then attribute that data to the specific gender. By doing so, one can see how time and experience can affect job earnings. Changes and transitions over time, including promotions, could be interesting information to apply to the wage gap issue.
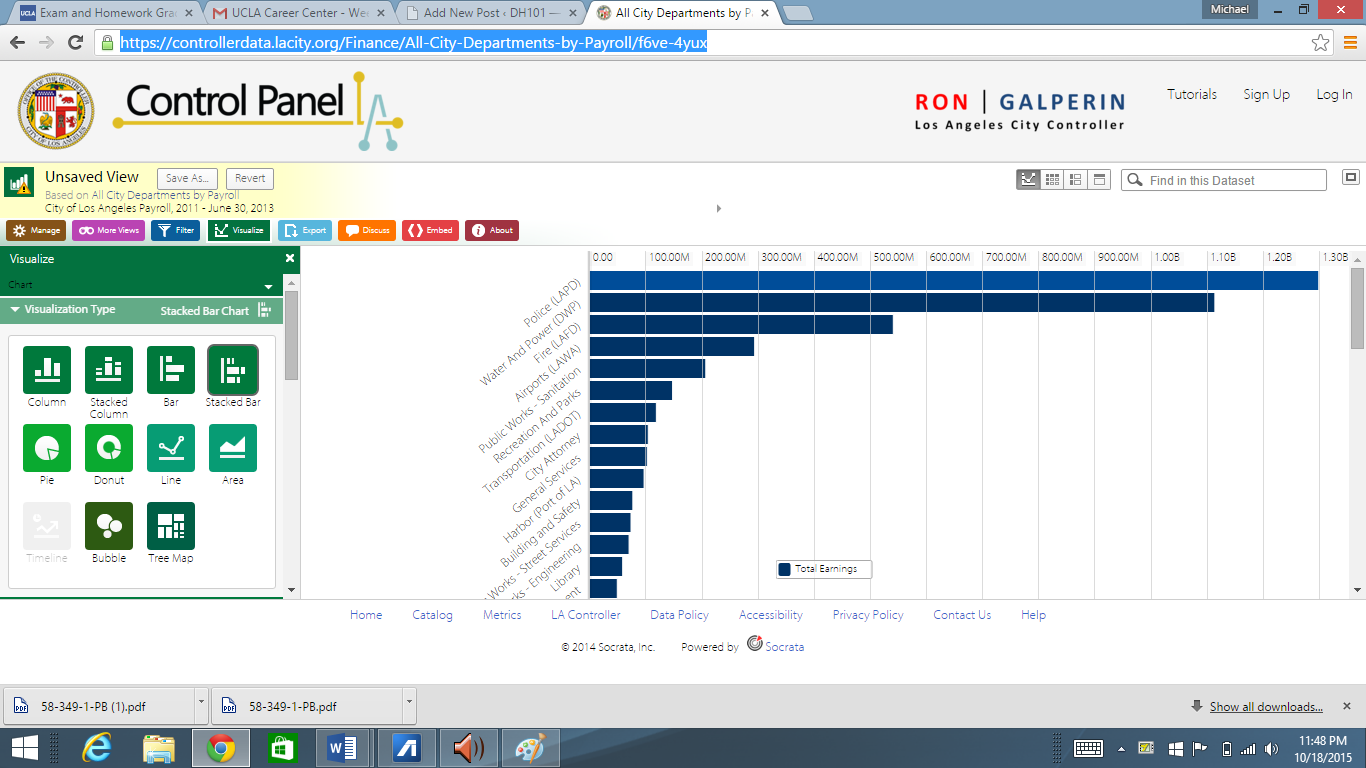



{kind=link}