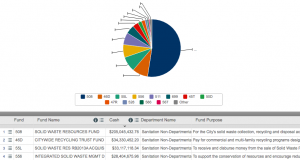
I chose to examine a data set from the L.A. Controller’s Office that focused and describes L.A. Procurement This category is under the label of “Purchasing” and when I followed the external link, I was prompted with a page that was titled, “Data Cards”. This data set is comprised of fifteen categories, each labeled by the name of the expenditure, the quantity of what was purchased, and lastly the final cost. A record set in this particular data set is comprised of a description, cost and date of purchase of a specific type of item. These records, constituted through a detailed description of the procurement detailing the date of purchase, cost, description of the item, and supplier. According to Wallack’s and Srinivasan’s definition of identification of a data set, this digital representation of various categories that are related to the Los Angeles Controller’s Office, of which there are records that detail the specific datasets within each category. However, Wallack and Srinivasan mention that the different representation ontologies may shape reactions to them in varying ways, so that it is very important to consider ontologies, their completeness, in addition to their overall quality for comprehension.
I believe the person that would find this data set more illuminating is someone who wants to know about the expenditures of the city. The ontology provided is completely monetarily based and someone searching for a deeper narrative may want to consider additional information to better understand the community itself and what that community requires as vital resources. This information would also be helpful to someone to is attempting to understand what the city government is allotting money for, and the exact quantities which could be cross referenced with a list of community needs so that someone could visually see what is being asked for and in turn, what is being provided.

 As Wallack and Srinivasan state, “States’ attempts to promote “development” are thus limited by the information loss between the community ontologies that define development and meta ontologies that guide their actions” (3).
As Wallack and Srinivasan state, “States’ attempts to promote “development” are thus limited by the information loss between the community ontologies that define development and meta ontologies that guide their actions” (3).