The short story I chose to analyze for my Network Graph is “Athena Sees Good Things for You” This is the story of Patrick Ryan, who was very desperate for a job and ran into a friend who suggested he apply for a job as a Copy Editor for an unnamed company. Patrick went to the company with his resume and got a short interest with a woman named Mindy, even though he had no experience as a copy editor. After briefly glancing at his resume, Mindy hired him on the spot. Patrick tried to figure out what this job actually entails but no one would give him a definitive answer. After three days of trying to figure out what he needed to do at this job under the supervision of his coworker Kim, he still had no idea what the company even did. When he asked people, they cryptically replied with “We sell things.” The only clue he saw on the wall was a poser of a beautiful blonde woman named Athena that said “Athena Sees Good Things for You.” Finally, Patrick decided to look up the company on google and found that it was a fraudulent company that was scamming people by pretending that there was a mystic fortune teller named Athena who worked for them and predicted the future and helped people become rich. It turns out that Athena never even existed. Patrick becomes fed up with this fraudulent and cryptic company, and quits while on his lunch break and never returns.
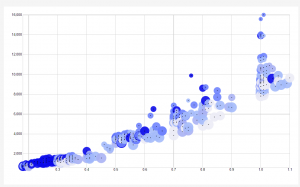
For my Network Graph, I chose to analyze the relationships between characters. In one column of my edge list, I had all the characters in the short story. In the next column, I had relationships between people, as defined by the conversations they had. I defined conversation as an unbroken dialogue between people. Finally, I included the weight of the relationship, which was defined as the number of conversations between two specific people. As you can see from the graph, Patrick Ryan has the most connections with all the characters because he is the narrator and the story revolved around him. He has the most conversations (6) with Mindy, his boss, and Kim, his coworker that was put in charge of training him. Patrick had the second most conversations with Inga, who was a kindred spirit and another coworker who actually exposed the ugly truth about the company they were working for. He also had brief one time conversations with the main boss (Lucien), the friend of his who got him the job (Debbie) and some other coworkers (Bald Man and Shriveled Woman). I also included the relationship between Athena and Betty, which Patrick saw in an email. Of course, Athena is actually a fictional person so we do now know the actual creator of the email, but she promises riches to a client named Betty.
The graph illuminates the strong connections between Patrick and Kim and Patrick and Mindy. It also shows us the background characters who did not have strong relationships with Patrick or anyone else.
However, there are a lot of limitations of the graph. When reading this story, I got a sense of very intense and powerful chemistry and bonding of Patrick and Inga. However, because they only had 2 real conversations, this powerful bond is ignored in my Network Graph. All in all, the complexity of relationships is ignored in the graph because the amount of times characters spoke does not tell us anything about their relationship.