This week, I read a short story by Callan Wink, entitled “One More Last Stand”, and created a network graph using Google Fusion Tables. This network graph serves to visualize the relationships between characters in the story. If characters mentioned or interacted with one another, I considered it a connection and used such data points to build an edge list. Network graphs are a neat way to display associations in a more understandable way. But, as with any graphic, there are restrictions to the amount of detail and accuracy included.

The resulting network graph [pictured below] successfully illuminates the frequency certain characters saw each other and accurately demonstrates who spent the most time together. However, it failed to accurately represent the closeness of all the relationships. For example, the story follows the main character, Perry, and the Indian women he is having an affair with, Kat Realbird, at an annual historical war reenactment. The graph clearly shows the weight of Perry and Kat’s affair, because they spent so much time together (they have 14 connections). However, it does not necessarily show the true importance and influence of other relationships they have – Perry to Andy, his wife, and Kat to John, her husband. Even though these are marriages and therefore close connections, the network graph only illustrates their weight as 4 and 2, respectively (as opposed to the affair that had a much stronger weight).
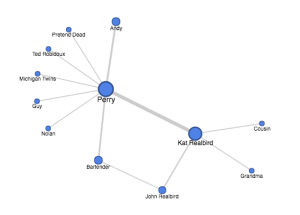
Another example of this type of graph’s limitations can be demonstrated regarding the relationships with the weight of “1”. Since I built the edge list around anytime characters interacted or mentioned each other, some connections seemed to have equal “weight”, when in fact the true relationships were very different. For instance, in the beginning of the short story, Perry asks about Nolan, and old friend who he has known for years. Later, Perry encounters a random stranger (labelled as “Pretend Dead”) who played dead in the war reenactment. Perry doesn’t not even talk to this stranger- he only shares a scene in the reenactment with him. However, both of these connections are given a “1” weight, and therefore seem equivalent on the network graph when they, in fact, are not. Mathematically, the relationships are the same, but in reality, Perry was close friends with one man and had never spoke to the other. These examples demonstrate the clear limitations to how much detail a network graph can really serve to show.
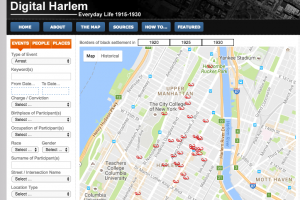 Although maps are often viewed as universally understood, factual, and objective, this is not the case.
Although maps are often viewed as universally understood, factual, and objective, this is not the case.
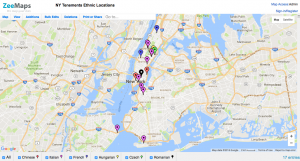
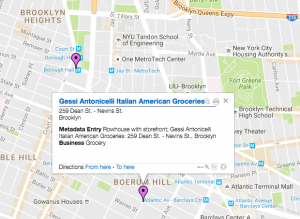
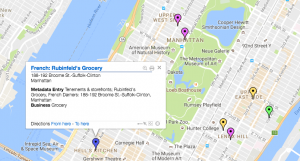
 As Wallack and Srinivasan state, “States’ attempts to promote “development” are thus limited by the information loss between the community ontologies that define development and meta ontologies that guide their actions” (3).
As Wallack and Srinivasan state, “States’ attempts to promote “development” are thus limited by the information loss between the community ontologies that define development and meta ontologies that guide their actions” (3).