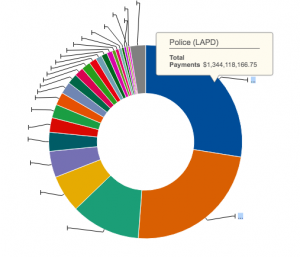
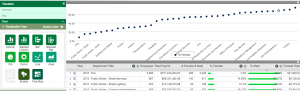
For my third blog post I decided to explore the Los Angeles City Payroll Calendar dataset. The data for each column entry includes year, month, month number, day, date and description. The description is what differentiates the data types between entries. The data types are broken down by payday types within a payroll calendar schedule that are important to the pay cycle so employers and employees know start, end, and holidays to account for.
A record is considered what day in the payroll cycle the entry is. The 5 types of days that matter in a payroll calendar are holidays, paydays, excess sick pay days, no deduction paydays or the day marking the end of the pay period. There are 255 records starting with January 2013 until December 2016.
Wallack and Srinivasan believe that the miss-interpretation of activities creates a divide between communities and the state because they emphasize different aspects of an issue. This inconsistency between the state and the community can represent an issue much differently than the people who are affected feel about the issue. They argue that ontologies are a shared platform in which individuals become part of a greater group; simultaneously this means that ontologies will create exclusion between groups. This will create divides between the groups understanding or interpretation of an event. The government or employers will have a different understanding for this data than the employees or lower class.
The data is organized chronological by year then month then day within the month based on its payroll type. Using this definition, I would say that this data’s ontology is based on organizing financials for companies to keep their payroll expenses easy to reference and verify.
This ontology seems to make most sense to an accountant. The chronological order of dates with the significant days within the payroll are most relevant to the accountant who would need to know the ending and beginning of pay periods and they go through the dates in that sequence.
This does not have much detail about which companies is following this payroll schedule, they also leave out any sort of numerical values if you wanted to compare pay periods to analyze trends within pay periods. I also would assume that different companies who have varying religious practices or are not a typical corporation would not all have this same payroll cycle. This dataset does tell me the generic payroll cycle for a company in LA and where the main control panel for organizing important dates is.
If you wanted to look at this from an economists perspective you could organize the payroll calendar by how much money was being paid within each of the pay periods, and could organize by company type and the company name with their total payroll expense for each payroll period to observe which months, weeks tend to have the most pay or when is the least. This information could be used to balance a company’s budget.