For this assignment, I chose to explore the short story Whatever Happened to Interracial Love? by Kathleen Collins from Granta Magazine’s 136th edition Legacies of Love, which was published on July 13 of 2016.
The story is set in 1963 and is about interracial romantic relationships. It focuses on these two roommates living on the Upper West Side—one ‘white’ and the other ‘negro’—who were in love with people of another race. It is told from the perspective of the ‘negro’ girl named Cheryl, but in the third-person narrative with the exception of several bracketed sections, which reveal her thoughts in the first-person narrative. Cheryl was 21 years old and the only ‘negro’ in her graduating class. She was in love with a ‘white’ freedom rider named Alan. Her ‘white’ roommate was named Charlotte and 22 years old. She had just graduated from Sarah Lawrence. She was in love with an Umbra poet named Henry. Cheryl and Alan had considered getting married, but Cheryl’s father couldn’t understand their relationship because of how much he had fought and struggled for freedom. Alan’s parents also disapproved of their love and forbad him from marrying her, which resulted in the end of their relationship.
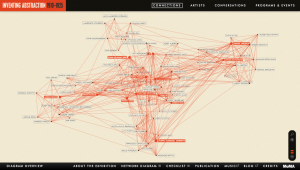
The characters in the story include the two roommates Charlotte and Cheryl, Henry, Alan, Cheryl’s parents, Alan’s parents, the ‘negro’ heroin addict named Skip, Charlotte’s friends Adrienne and Derek, the Father of the Movement, Mrs. Drexel who was Cheryl’s old librarian, the ‘negro’ photographer, the ‘white’ women from the prayer vigil, and the ‘negro’ women en route to Itta Bena. A connection is formed between these characters through an interaction or the sharing of a space.


The network graph consists of circles representing each character from the story. It centers around the main character and forms a line between the characters who formed a connection. When a circle representing one of the characters is clicked on, his or her connections are bolded. The circles are of different sizes, depending on the number of connections that each character had, which was very interesting. However, I thought it would make more sense to differ the sizes of the circles according to the character’s involvement and significance in the story. For example, since the story is primarily about Cheryl and her relationship with Alan, the circle that represents Alan should be made larger to bring more emphasis to their connection. Another limitation about the graph is that viewers can’t tell what type of interaction occurred or how strong each connection was. For example, the interaction between Cheryl and the photographer was very minimal and one-sided because they merely shared the same space and Cheryl spotted him heading towards a pawnshop.