For this week’s blog post, I decided to analyze the ontology of the Payroll by Departments data on the LA City Controller website. This dataset includes information about the fiscal year, position being paid, the job class title, employment type (full-time or part-time), hourly rate, projected annual salary, each quarter’s payments, base pay, total pay, benefits payments, and more. A record in this dataset is each of the 33 data types defined for each row.
According to Wallack and Srinivasan, an ontology is “a system of categories and their interrelations by which groups order and manage information about the people, places, things, and events around them.” I would describe this dataset as being a state data system, with a state-focused ontology. Though this is from the city controller’s office, Wallack and Srinivasan described that state data systems offer the infrastructure of administration, and in this case, the payroll is at the core of the city’s functionality.
This dataset is clearly published as a way to establish transparency between the city and its residents, so the residents can know how much money goes to each position and can see what the financial priorities of the city are. When someone clicks on, say, the Elected Officials data, that resident would know how much individual City Council Members are making off of their elected positions. To further lend itself to transparency, some of the categories are even defined at the top so people know what the data means.
However, this data appears to be left intentionally vague. For instance, we know that we are looking at a Council Member’s data, but we don’t know which Council Member we are specifically looking at, so if there was an issue in the data, like maybe one Council Member accepted a huge bonus, we wouldn’t know how to hold that one person accountable. There is also an information overload in this dataset. There are so many columns of information, it would overwhelm a resident looking for information.
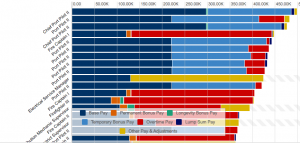
Another issue with the presentation of this data is in its visualizations. When you open the dataset, its first visualization is a pie chart of each department and how large its percentage of the overall city payroll is. It only tells you the amount of money paid in payroll to that department, but gives no context as to the makeup of that department. A resident would have to delve into the depths of the data to understand that, which is time consuming, overwhelming, and unnecessary. Perhaps if more information had been put into the data visualizations, they would have been more useful. What is clear in them, however, is what the city wants to project as its departments of priority. A city resident could look at the data and be pleased that the city values keeping its citizens safe and healthy, with police, water and power, and fire earning the most payroll. While these are major categories earning a lot of money, there is also departments like “Harbor,” but the visualization offers no explanation about the department, what it does, or who is being paid the over 97 million dollars listed.
If this were coming from the residents of the city, the information would look a bit different. The main focus might be on positions of power, how much they are making in total, how much work they are actually putting in, and how this relates to other cities and the overall city budget. I would be wondering how much of my city funds are going to these individual positions, especially with the public positions earning in the top 1% of the country. I would want to be answering questions regarding why and how my money is going there and its effectiveness rather than simple numbers about what percentage over base salary it is.
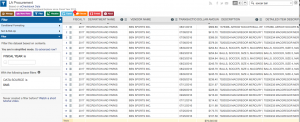
 Row ID, Year, Department, Title, Payroll Department, Record Number, Job Class Title, Employment Type, Hourly or Event Rate, Projected Annual Salary, Q1 Payments, Q2 Payments, Q3 Payments, Q4 Payments, Payments Over Base Pay, % Over Base Pay, Total Payments, Base Pay, Permanent Bonus Pay, Longevity Bonus Pay, Temporary Bonus Pay, Lump Sum Pay, Overtime Pay, Other Pay & Adjustments, Other Pay (Payroll Explorer), MOU, MOU Title, FMS Department, Job Class, Pay Grade, Average Health Cost, Average Dental Cost, Average Basic Life, Average Benefit Cost, Benefits Plan and Job Class Link. While there are 285008 rows stored, a record in this specific dataset refers to the aforementioned profile of a department in the city.
Row ID, Year, Department, Title, Payroll Department, Record Number, Job Class Title, Employment Type, Hourly or Event Rate, Projected Annual Salary, Q1 Payments, Q2 Payments, Q3 Payments, Q4 Payments, Payments Over Base Pay, % Over Base Pay, Total Payments, Base Pay, Permanent Bonus Pay, Longevity Bonus Pay, Temporary Bonus Pay, Lump Sum Pay, Overtime Pay, Other Pay & Adjustments, Other Pay (Payroll Explorer), MOU, MOU Title, FMS Department, Job Class, Pay Grade, Average Health Cost, Average Dental Cost, Average Basic Life, Average Benefit Cost, Benefits Plan and Job Class Link. While there are 285008 rows stored, a record in this specific dataset refers to the aforementioned profile of a department in the city.

 on soccer balls, but buy clicking the information one will immediately notice that about 81,000 adults and youth participate in the City’s organized sports leagues.
on soccer balls, but buy clicking the information one will immediately notice that about 81,000 adults and youth participate in the City’s organized sports leagues.