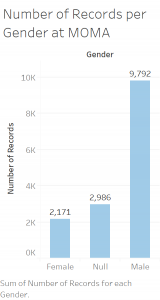
For this week’s blog post I chose to read Whatever Happened to Interracial Love, a short story by Kathleen Collins that appears in Granta 136: Legacies of Love.
Whatever Happened to Interracial Love follows the experience of Cheryl (whose name is only revealed at the very end of the story), an African American woman living in NYC in 1963. Cheryl is in an interracial relationship with Alan (identified as “white freedom rider” initially), and much of the story revolves around how people in Cheryl’s life react to the relationship. There’s Charlotte, her bohemian college-liberal roommate, and her yuppie friend group who react a little too enthusiastically, contrasted with her and Alan’s parents reaction of disgust. Cheryl is a dynamic character trying to come to terms with the expectations she places on herself, along with those placed by her parents and society going through an upheaval.
I made a simple network graph using Google Fusion Tables to outline the various relationships that exist in the story. I defined a relationship as any interaction one character has with another (whether it is active conversation, flashback, or the narrator mentions each other being together, all of these interactions are weighted equally). The characters are the nodes while their interactions are the edges connecting them.
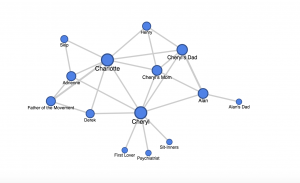
My network graph’s strength lies in its display of centrality. It is clear that Charlotte and Cheryl are the main characters due to their centrality in the network. They exhibit degree centrality, for they are the one’s who have the most interactions in the story, thus they have more edges connecting to more nodes.
My graph leaves much to be desired in terms of analysis; it is an unweighted network. While it shows who the main characters are, it does not demonstrate the significance of the side characters, for each is weighted equally. For example, Skip and Alan’s dad are both off to the sides of the network, giving off an impression of equal insignificance, but Alan’s dad actually plays a much more prominent role than Skip.
If I were to go deeper with my network graph, I would correct it for significance by making certain nodes (of the more important characters) larger. I would also incorporate different colors to show who belongs to what friend group (Alan’s Parents are one color, Charlotte’s friends another).