For this assignment, I was interested in the Diamond Prices Database. This database included prices of cut diamonds, along with data on color, clarity, and ratings agency. It was taken from the Journal of Statistics Education online data archive. It includes data from 308 round-cut diamonds, taken from a newspaper ad. It had a column for ID number, color, clarity, rater, and price of the diamond. I had to manipulate the data-set itself in order to make it presentable in a visual way.
The first thing I did when I opened the data-set was remove the column for Identification Numbers because this was just numbers 1-308 numbering the diamonds in order. It was useless to me. Then, I deleted the column called Rater, which showed which one of three independent rating agencies rated the specific diamond. I was not interested in who rated the diamond, so this information was useless to me.
The next thing I did to the data-set was change the Color column from alphabetic data to numeric data. Color refers to the degree of color purity in the diamond. In the legend of the data, it said that the color of the diamond was rated on an alphabetic scale from D-I, where D represents the top color purity grade, lesser than D is E, then F, then G, then H, then I. I though that numbers from 1-6 would do the exact same job of representing the color purity of the diamond, and would be easier to present visually. I changed all the D’s to 1, then the E’s to 2, then the F’s to 3 then the G’s to 4 then the H’s to 5 and then the I’s to 6. In my opinion, using an interval scale from 1-6 to rate color with 1 being the best and 6 being the worst color is much more clear and simple than using letters of the alphabet starting with D to represent color, so that is why I made this change in the data-set.
Finally, I copy and pasted all this new data into RAW. I chose to use a scatter-plot to analyze and present the data.
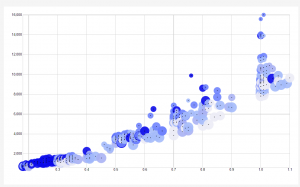
The X-Axis of the scatter-plot corresponds to the weight of the diamond, in carats. The Y-Axis of the scatter-plot corresponds to the price of the diamond in Singapore dollars. The size of the radius of the data points corresponds to the color, where the smallest data points have a color rating of 1, which means that they are the best color. In other words, the smaller the radius of the data point, the better the color and the bigger the radius of the data point is, the worse the color is. The color of the data- points correspond to their clarity (presence or absence of minute flaws). In the data-set, IF means internally flawless. Below IF, the second best clarity is VVS1, which means very very slightly imperfect, then VVS2, then VS1, which means very slightly imperfect, and finally the worst clarity is VS2. I created a blue color scheme to portray clarity. The brightest blue represents the best clarity (the IF), and the second brightest blue represents VVS1, then the third brightest blue represents VVS2, and so on until the worst clarity is associated with the lightest blue color of the visualization.
I love my visualization and I am very proud to have created it. I think that it is the best visualization for this type of data, because the most interesting component of the data is the weight of the diamond vs the price. This visualization shows me that generally, as the weight in Carats goes up, the price of the diamond goes up. This is interesting and it shows me that weight is really the biggest determining factor of price. Weight matters much more than color and clarity when determining price, because the size and color of the data points (corresponding to color and clarity, respectively) fluctuates over the entire graph. However, there seems to be a strong positive linear relationship between price and weight of the diamonds, as seen in the X and Y axis.
Another very interesting thing that the visualization shows me that I never noticed in the data was the fact that the diamonds with the best clarity as generally the smallest diamonds. I can see this because the brightest blue points are clustered near the bottom left of the graph, which shows that they are the smallest and cheapest diamonds. It seems that clarity decreases generally as size increases. This makes sense because the bigger a diamond is, the more space there is for imperfection.
Another interesting thing that I noticed in the visualization was that all the outliers (the points that do not strongly adhere to the positive linear relationship between weight and price) are all tiny data points, which mean that they are the best color. This shows me that diamonds with exceptional color can be sold for more than they are worth from weight alone. So even though weight heavily determines the price of a diamond, it appears that diamonds with amazing color have the ability to be sold for more than their weight is worth.