This week’s readings immediately made me think of Spotify’s music library. Though it is not an index of multiple different types of data, it does hold immense amounts of information. As a Spotify user, I am able to enter into different genres, artists, and playlists easily and efficiently in everyday life. If I remember a song from my childhood, or need to remember the lyrics of a song, I can instantly access that information. Spotify acts as an example of a database that I utilize every single day, however the importance of these electronic databases extends past convenient music on demand.
As a World Arts and Cultures major, databases have become a saving grace for me during finals weeks. Through museums such as the Fowler and Hammer, I am able to access art pieces based on the specific requirements I need. To elaborate upon the concept of databases being used to “help people keep track of things”, these museums’ databases give individuals an understanding of not only the specific dimensions of an artwork, but also an understanding of the culture it comes from and the ideas behind the piece.
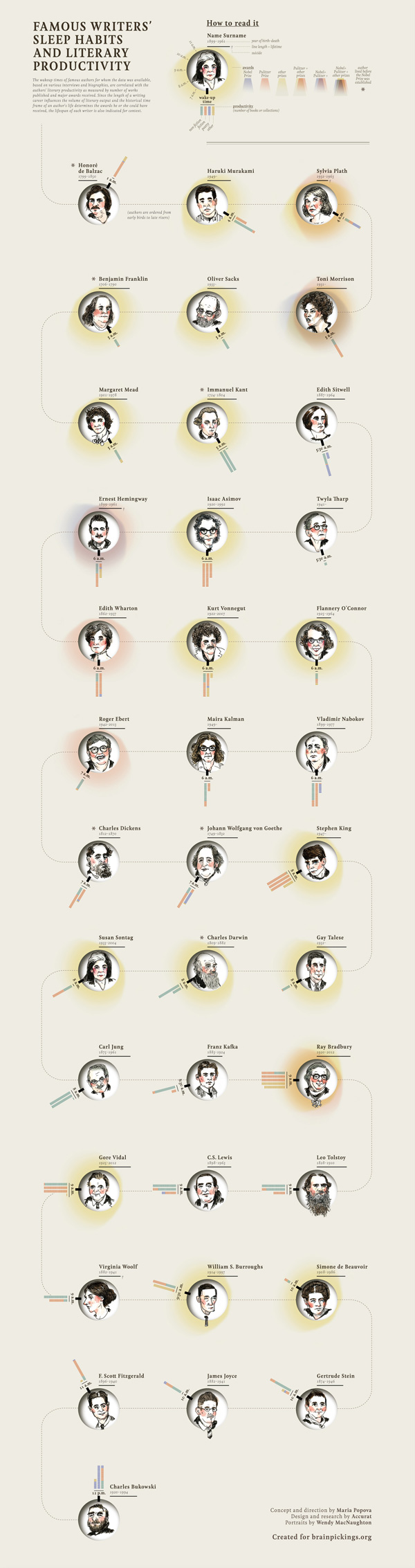
In a world that is constantly evolving and reinventing itself, databases ensure that we will not loose the very aspects of society that have come to define us. Historical documents, controversial articles and photographs of protest help our present society to progress, while still considering the steps that were taken in the past to get to the present. .
Just as Spotify helps me to discover new and old music, art databases help me to discover new cultures and new ways of thinking. I am able to learn about the artist, witness the final project, and gain insight into more information about the piece. Both aspects of culture help to support a constantly growing and changing society because they give society an opportunity to preserve the past, without being altered, as changes continue to develop. Essentially, databases can be snapshots of history, each documenting a different aspect of the human experience.










{kind=link}
{kind=link}