For week 6, I particularly enjoyed the reading about Demystifying Networks. In this blog entry, Scott Weingart laid the groundwork for understanding networks. Although I had an idea of networks before reading this article, there were definitely some elements of networks that I didn’t really understand, so just ignored. The detailed post explained each level of the network.
Scott explains that a network is made up of stuff and really any stuff. Each item of stuff is referred to as a node. These nodes are then divided into different types of nodes. For example titles of books and authors of books would be two different types of nodes. The relationships between these nodes are referred to as edges. He explains that a key to these edges functioning properly is that edges can only connect two different types of nodes and not nodes of the same type. There are also two different types of edges that can connect the nodes. A directed edge describes the kind of edge, with which you cannot swap out Node 1 and Node 2. The other kind, unsurprisingly, is an undirected edge. With an undirected edge, Node 1 and Node 2 can be interchanged and are connected with a simple line.
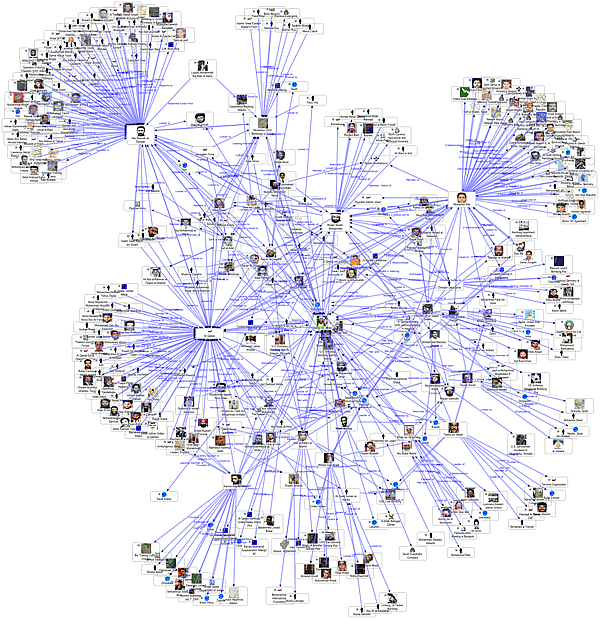
When I think of networks, I immediately think of social networks. As a “millennial” our lives are completely intertwined with social networks. Most of our interactions are even through social networks like Facebook or twitter. After reading this article, I tried to relate it to what I believe is the most notable social network: Facebook. It was easy for me to identify that people were the nodes, so in Facebook terms, each profile would be considered a node.
I determined that although Facebook is a vast and complicated network. In the terms that I had just learned, I could only make sense of Facebook as a unimodal network. If Facebook mainly just contains simple connections between one type of node, each friendship would be considered an edge. Because there is so much more that goes into Facebook, I was confused that there were not more types of edges, and that I couldn’t see it as a multimodal network. I thought of the different groups that were made on Facebook and how that could be displayed visually without being confused for friendships.
I can see how people on Facebook, if not connected by friendships, could each be connected to the groups they belong to, in a multimodal network. This would form a very interesting web, but only be illustrating the group aspect of Facebook, and disregarding the friendship aspect. Overall, I am excited to have made progress understanding networks, and although I believe I could make interesting specific networks relating to real life, there are still many things I don’t understand about the networks I interact with in daily life.










{kind=link}