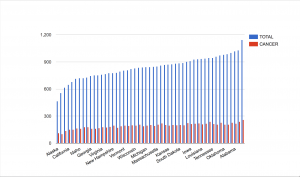
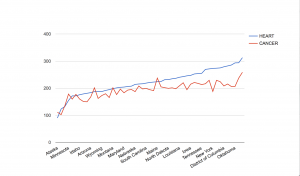
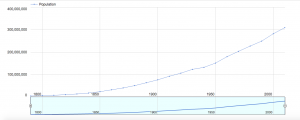
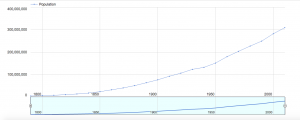
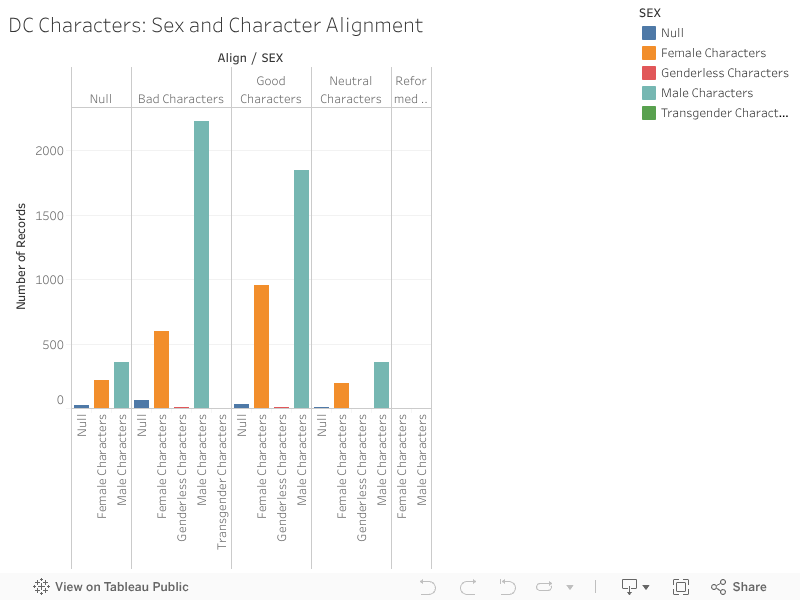
For this assignment, I chose to explore death rates of each state for various causes: heart disease, cancer, stroke, respiratory disease, accidents, vehicle-related accidents, diabetes, Alzheimer’s, flu, nephritis, suicide, homicide, and AIDS. The dataset also provides information on population, age distribution, and urbanization, which may allow viewers to find correlations between these factors and the various causes (e.g. higher deaths caused by respiratory disease in more urban regions). However, the time period on these death rates was not provided so I was unable to tell which year these deaths occurred in.
Since the data was already categorized by state, it would make the most sense to present it on a map. However, as the data contains various data types and measures, it may be difficult to present all the information without overloading too much on a single map. What I have done to divide up the dataset is separate each data type into different maps, which would make it easier for the viewers to comprehend the data. In addition, the maps are color-coded with the darker-colored circles showing higher rates and the lighter-colored circles showing lower rates. The size of the population is proportional to the size of the circle. Thus, the bigger the circles are, the larger the populations are and the smaller the circles are, the smaller the populations are. Hovering over each circle can offer more details about each state.
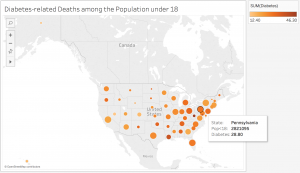
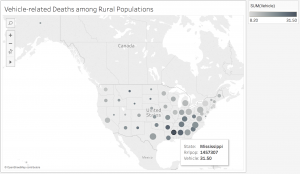
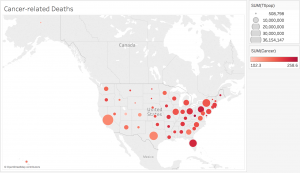
While geocoded maps are great at pointing out which states have the highest death rates for each cause, they make it difficult to establish correlations between the causes and the factors such as age or urbanization. In addition, in order to better determine these relationships, more information would be necessary. For example, data on other factors, such as air pollution or vehicle use, would be very useful in order to figure out if urbanization contributes to higher rates of respiratory diseases and related deaths. Since the dataset covered so many various causes, but lacked detail on the factors that could play a role in these deaths, it was difficult to create an overall visualization that would sum up the dataset. Perhaps a stacked bar graph would have been a good option for data visualization because the comparison of the ratios of deaths to the populations would be more visible.