For this week’s blog post, I decided to write my piece on the “Eight Trains.” The Eight Trains is about a man living in rural Japan, writing a narrative about his journey to and from his workplace. There are 8 trains he must take every day, 4 to get to the workplace, and the same 4 trains going back. He writes down all the details that stands out to him about the people in each train that he takes every Tuesday.
For my edge list, I used the columns of person and train. The persons column consists of only the narrator, because the story is being told in his point of view. Unlike many other stories, where there are multiple characters with multiple interaction between different sets of people, this story is about from the author’s point of view. Furthermore, I decided to use trains because each sets of train means different sets of interactions and people. I also decided to include the weight here. The weights are there, with one weight indicating one person that the author felt interesting enough to explain in his short narrative.
Thus, my network graph looks as follows.
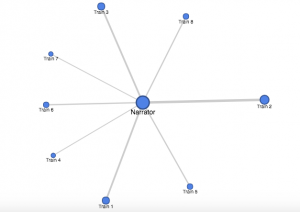
Clearly from the graph, we can see that each train (and thus, different sets of people) have less or more influence. The first noteworthy observation for those who didn’t know the story is that all the trains are connected to the narrator, there are no interactions between the trains. There is a clear center point here, indicating that there is a sort of “main character,” in this case being the author of the short story writing about his experience with Japanese train system. Another observation from the graph that train 2 had the most interesting sets of people. Not only is the train 2 the biggest node with the thickest edges, it is the most separate from the other groups.
Unfortunately, there are some limitations, in which some information are missing. For example, it would have been nice to Train 1-8 circle around the train in numerical order. If this was the case, we can sort of see the general trend of how interested the author was in each train. If we change the graph with the aforementioned changes, we would clearly be able to see that the author was more alert in the morning especially with train 2. However, as the day progresses, he loses more and more interest. Especially after train 5, which is his ride home, it becomes clear that the author has no more interest and is only thinking about getting home.