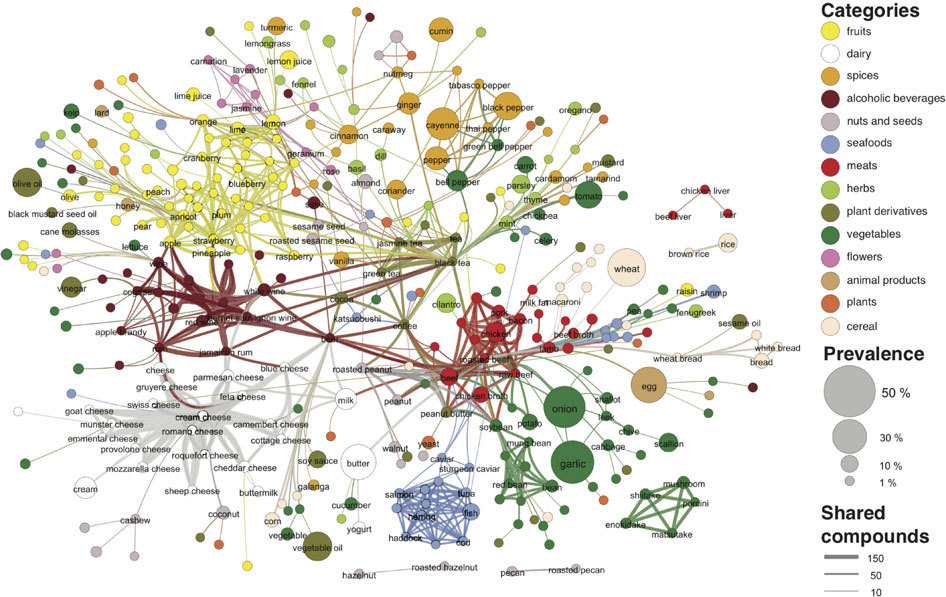
I did not realize how text analysis could help discover more about the actual subject and perhaps help form an argument or additional conclusion about the text. Reading about Andrew Smith’s commentary on the Criminal Intent Project and the text analysis of all the Old Bailey court cases from 1674 to 1913. They analyzed 198,000 trials. Researchers found that beginning in 1825 there was an unusual peak in the number of guilty pleas and short trials, whereas before 1825 most of the trials were full trials in which people did not plea guilty. Researchers also found that the number of men defendants started to outweigh the number of women defendants. These findings helped to advance the understandings of the Old Bailey court cases and helped to gain more insight on the changes in the history of court cases in London.
Until I was exposed to text analysis in Digital Humanities and did a little more research on the background of text analysis tools like Voyant I did not realize how helpful of a tool it is. Reading about some background information, I learned that Voyant credits some of its textual analysis skills towards Google because like many other search engines Google focuses on search and retrieval of text content. It also references how Google sets a “standard for simplicity in interface” when browsing the default search page. Now compare the default search page of Voyant to Google and how the Voyant search page includes one box to begin text analysis. I recognized that Voyant and Google are similar in the aspect of simplicity because of the inclusion of a single search box. I did not think of Google, something I use everyday, as a type of text analysis. Learning more about the process of analyzing text and how it can lead to retrieving new texts or formulating new arguments has been useful for my DH project research. Text analysis is something I hope to use more of throughout my research projects.
http://docs.voyant-tools.org/context/background/