http://www.archaeology.org/travel/interactivemap-texas/
- Alan McConchie and Beth Schechter, “Anatomy of a Web Map” (click each slide to advance)
- Jim Detwiler, “Introduction to Web Mapping“
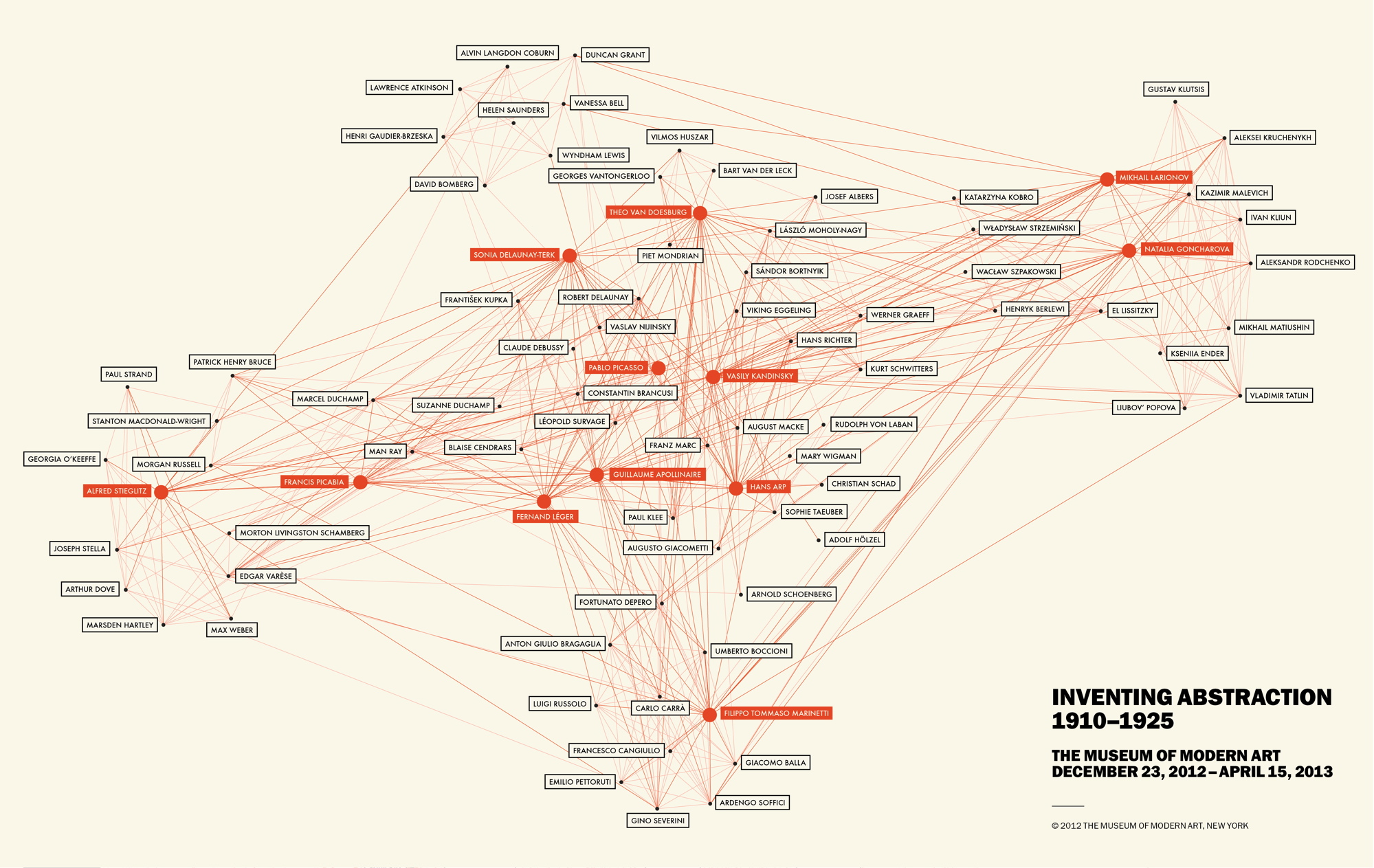
Both the Intro to Web Mapping and Anatomy of a Web Map were excellent tools in understanding the development of web maps over time. This evolution began with the incredibly simple static map, which was essentially a paper map that had been digitized, and is still very commonly used in research or visual representations. The first great evolutionary leap was to dynamic or distributed maps, which reflected changing data by loading and presenting a new, current data set each time. These dynamic maps are ideal for things which we need up-to-the-minute information on, although they are also applicable for use with data sets which change more slowly. The next step were animated maps, and “real-time” maps that are essentially dynamic maps automated and linked to sensors which provide the real time data. Finally along came Google Maps (interactive maps) with their ability to toggle layers on and off, link map features to external websites, etc., followed by the analytic map which used these interactive features for more in depth analysis of the data. The final stage, collaborative maps, are connected with distributive maps in that they have multiple sources – in collaborative mapping, anyone can contribute. A good example of an interactive, potentially analytic map is the one linked about about the different types of archaeological sites in Texas.
However, I wonder why no one has made mention that the use of maps for analysis, and even interactive maps (though not in the digital sense), existed long before the web, when maps were only on paper. Detwiler only details this evolution within web or digital maps themselves, even though humanist scholars have been using maps for analysis for decades. In much the same way as the Texas map above allows you to click on a site and read about it, so paper maps had sites or buildings within sites marked in order to reference you to a discussion somewhere else in the text. For instance, archaeological site reports often have a map with locations or buildings labeled (toggle ON your label layer), which you can then reference in the text (not quite a pop-up explanation box, but the same concept). Also in trying to understand the development of the state, archaeologists often plotted things like trade routes of least energy consumption (‘shortest route’ option rather than the ‘lightest traffic’ option).