Museums have increasingly been joining the global movement for open data by opening up their databases, sharing their images and releasing their knowledge.
This week, Mia Ridge’s Cultural Data in Museums discussed how museums are making available their content and knowledge to the general public by utilizing open cultural data–that is, data that is made available through “machine-readable formats” by cultural institutions under an open license. This data includes anything from metadata, narratives, bibliographies, quantitative records, and so forth; and the open license gives access to anyone from outside the institution whom created it by clarifying permissions and restrictions.
I hate to bring this up but I can definitely relate this week’s reading to my team’s DH101 project last quarter, where we explored the Tate Britain’s collection of Joseph Mallord William Turner’s paintings. With the Tate Britain granting us access to their open cultural data via an (extremely comprehensive) Excel sheet of the collection, we were able to analyze and explore the data to ultimately contribute a unique interpretation of their collection.
In Cultural Data in Museums, Ridge goes onto conclude that open cultural data ultimately unlocks great potential for the museum to spread knowledge due to its web data’s networked nature. That is, each cultural dataset added contributes to wider knowledge and creates new possibilities for innovative experiences of shared cultural heritage. I feel like our website kind of exhibits this. The Tate giving us their open cultural data for us to form our own narrative and interpretations, it could potentially lead to a domino effect of other people seeing our website and then wanting to explore the data on their own to form their own analysis separate and unique from ours’. Take for example one of our tabs on the website, Travels, which looked at Turner’s paintings in relation to his travels through Europe.
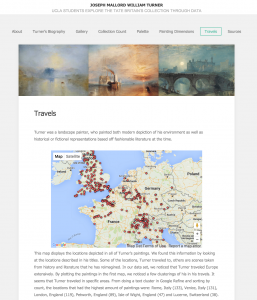
Here lies the potential for someone to look even further into this data than we did to come up with an argument that may have not yet been brought up. Through this, I can definitely see Ridge’s point of the networked nature of open cultural data. Open cultural data leads to projects such as that of DH101, which can then possibly spark curiosity in someone else to further interpret the open cultural data, adding to network of knowledge.