Reading “What’s Next for Open Cultural Data in Museums?” by Mia Ridge really intrigued me with the relevance it has on recent exposures or reformed licensing for creating digital applications. Ridge first explains what open cultural data is, being “data from cultural institutions that is made available for use in a machine-readable format under an open license.” While this allows much potential and possibility in how museums can use supplementary digital methods to better visitors’ experiences or understandings of the collections, open cultural data can also be misused by becoming digitized. Ridge says, “Open cultural data could be as simple as publishing a downloadable text file.” From one perspective, this is a great way of exposing cultural data to the general public, letting people use the content without any extreme repercussions that may come with copyright restrictions. On the other hand, Ridge also determines that some open cultural data is overlooked; obstacles resulting in this includes confusing licenses, poor record quality of data, lack of general interest, and overall ambiguous data.
The statement by Ridge reminded me of the projects we had looked at for Week 1, where we examined digital projects to get a grasp of how technology either adds or detracts from the experience museums are trying to create for visitors. My table was give the “TateBall” app for iPhone. Users shake a magic “Tate-ball”– the app calls upon temperature, location, and time of day to pick out an art piece from the Tate Modern museum. While pretty cool and does amplify the involvement of visitors at the Tate, my table had agreed that no educational purpose came from the app other than being introduced to art pieces we haven’t known about before. This then ties back into how Ridge is certain in open cultural data’s purpose being generally misunderstood by developers, programmers, and museums, as she later concludes “There is often a tension between the need for easy-to-use datasets using common vocabularies for simple ‘mash-up’ style applications and the need for more sophisticated data structures… to support internal uses, partnerships between museums, libraries and archives, or for use in research-led projects.”
“…Open cultural data projects seem to work better when they set aside resources for community interaction…”
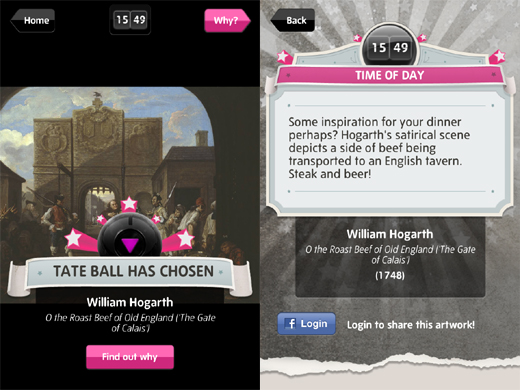
I definitely agree with her, since the digital app of the TateBall had potential in improving audience interaction, but didn’t deliver any resonance for it; it could be possible that the app developers used a dataset that only provided the very basic information about the Tate collections, and nothing further? Nothing about why these art pieces are housed in the Tate, where they come from, or why they were created is given in the app; users are left to either speculate about the app’s intentions, or they are left confused and gain little knowledge about the pieces, thus reducing the effect of resonance. It could also be said that perhaps an app like the TateBall does nothing to enhance experience; maybe it’s just the fact that it being digital detracts from the art, in this case, and therefore could detract from the great potential that the open cultural data had. All in all, open cultural data faces a huge grey area in how we interpret the data and decide to use it, as well as how our intent of opening it up- it’s very existence, even- to the public is called into question if delivery methods such as digital mediums aren’t effective.
I think the Tate Ball is an example of the concept of data for data’s sake that we discussed in class. In a lot of cases, the meaning of museum data really comes from the user, rather than the information itself. The people who developed the Tate Ball saw the data as a means to a fun way to engage an otherwise uninterested (perhaps?) audience, and used it to that end. Someone could’ve easily taken the same data and made a very informative, research-based app, and even then, people could’ve drawn completely different conclusions, based on how they viewed the data. It’s all in the eye of the beholder.