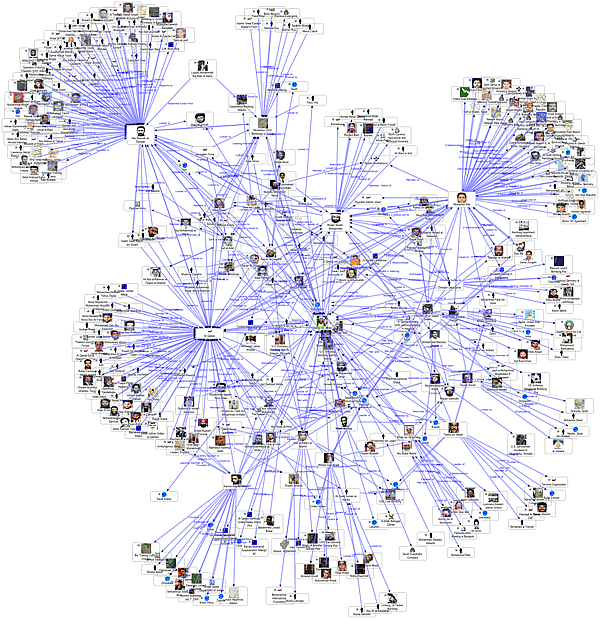
After reading this week’s articles about networks, the various social networks I use were the first things to pop up in my mind (probably since I use these almost every day). For example, Instagram is a social network where friends can connect and share pictures with each other. Also, people can follow various celebrities and or favorite business to stay updated on all of their activities they wish to share. The two nodes involved with this social media are the user and their pictures. Thus, Instagram is a bimodal network. These two nodes are connected by an asymmetric edge; the edge in this case being “is the photographer of.” For example, “user A is the photographer of picture B.” However, one cannot switch the two nodes around, as in “picture B is the photographer of user A,” thus the asymmetry of this edge, called a directed edge.
However, Instagram is considered a social network because there are edges not just between user and picture, but between users and other users, other users and pictures, and pictures and other users. Users can connect with other users by following them, in which the second user may choose (or not choose) to follow back. Depending on if the following is reciprocal or not, this edge is either an undirected edge with a symmetric relationship (“user A is following user B” and equally “user B is following user A”) or a directed edge with an asymmetric relationship (“user A is following user B” but not vice versa because user B did not follow user A back). Users can “like” another user’s photo, thus connecting other users with other photos in an asymmetric directed edge (“user B likes user A’s photo”). One user’s photos may have tags of other users in them, connecting photos with different users in another asymmetric directed edge (“user A is tagged in user B’s photo”). From my understanding of what a dense network is (which may or may not be correct), Instagram serves as an example of one. A user and his photos are connected to other users and their photos in multiple edges, linking the social world together through a variety of interwoven relationships. Algorithms can detect trends in connections and put together a string of suggested photos a user may like based on similar connections of the other users they follow. More and more so, social networks are becoming a platform to discover new interests and people to connect with, in addition to connecting to friends and interests one already has.
http://instagram.com











{kind=link}