
http://www.aaronkoblin.com/work/flightpatterns/
Demystifying Networks by Scott Weingart describes the beginnings of networks and how they can be used today within the digital humanities setting. Before the reader gets too excited on networks, Weingart gives a few warnings when dealing with networks – 1) yes networks can be used on an project, but that does not mean they should be. Networks only work for certain projects, and we must not get carried away when using them otherwise they will appear and become misused. 2) “methodology appropriation is dangerous” in that the methods and procedures one used on one network are not the same when working with a different set of data. Borrowing these methodologies can be even more dangerous because the users lack the knowledge to apply them correctly.
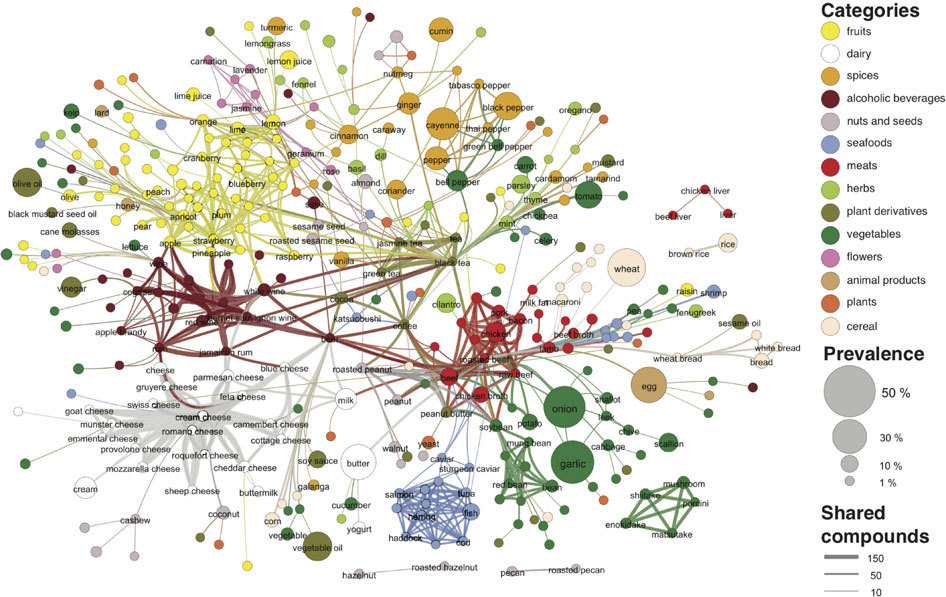
Weingart also covers “stuff”. Within his topic of stuff there are nodes, the connectors and organizers between the stuff. Nodes have attributes, or contain data on the stuff. Demystifying Networks uses books as the example of stuff. Different examples of books (dictionary, Poe collection, Harry Potter, etc) are the nodes. The title, number of pages, and author are node attributes. The next overarching topic is “relationships”. Weingart nicknames them “edges”, and defines them by the nodes that they connect. Continuing the book example, he takes person Franco Moretti and lists the edges that contain Franco Moretti – that he is an author of Modern Epic and Graphs, Maps, and Trees.
I took a network created by a UCLA alumni and applied what I learned from Demystifing Networks. Aaron Koblin is a Design Media Arts graduate (especially cool since I’m also in DMA) who represented visually and interactively the network of flight patterns across the United States. The project is part of a series called Celestial Mechanics, “a plalanetarium-based artwork installation that visualizes the statistics, data, and protocols of manmade aerial technologies. However, these specific renderings show the altitudes, makes, and models of over 205,000 different aircrafts being monitored by the FAA on August 12, 2008. You can filter which aircraft you wish to see, zoom in on specific areas of the map, and even download high quality images for your desktop backgrounds because the resulting maps are so gorgeous.
With this example, defining the stuff, nodes, and relationships are more difficult because there is no database available to the public. I can say that the stuff is each individual airplane with its unique destination; the nodes are the airports (connecting the planes together); the attributes of the stuff is the aircraft, its altitude, the number of passengers, the flight number, etc; the attributes of the nodes is the size of the airport, the address, how many terminals it has, and if it’s an international airport or purely domestic; and finally, the relationship between the planes and airports could be which airline owns the plane and if its available at the airport. Visually, I don’t think there’s a more stimulating network graphic than this one. But with the promising future of networks, undoubtedly someone will take inspiration from Koblin’s work and stretch the boundaries of beautiful network visualizations.



{kind=link}