As part of the Digital Humanities 101 course at UCLA, undergraduate and graduate students reconstructed the history of silent race films from 1909-1930, a period often neglected. There exists no clear or consistent definition for the term “race film” amongst scholars, and thus the students discussed the extensive process they undertook to arrive at a suitable definition for their project. For them, a race film was a film with African-American cast members, produced by an independent production company and discussed or advertised as a race film in the African-American press. From there, they create an intuitive and interactive database predominantly containing information on films, actors, and production companies.
Sources:
Although very few of the early race films survived, historians over the last 4o years have painstakingly pieced together evidence from various paraphernalia generated by the industry, including posters, newspapers, advertisements, theater programs, and handwritten notes. As a result, the students’ database drew from a wide range of sources, including 12 primary sources and 15 central secondary sources. Two of the key sources included the George P. Johnson Negro Film Collection, a donation to UCLA containing 71 boxes of material related to African Americans in the US film industry and the Mayme Clayton Library and Museum, which included over two million rare books, films, documents etc chronically the history and culture of African Americans. Historians have meticulously corroborated over the years to create an intensive collection of sources for the students.
Processes:
In compiling the dataset, the students first begin with an extensive process of studying the historical context of race films and then defining it- a crucial step in narrowing or expanding the sources they will work with. From there, they organized their data into a relational database spreadsheet, hosted by Airtable and categorized into People, Films, Companies, and Sources. Additionally, they provide a data dictionary to help navigate through controlled vocabulary used, including field name, data type, and description.
Presentation:
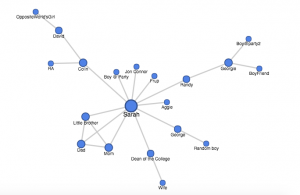
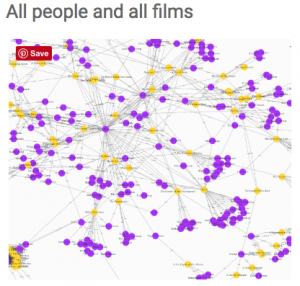
To better display connections across the data, the students create visualizations. Specifically, they utilize plot.ly to create a histogram to demonstrate the peak of race film production in 1921. They created two network graphs representing connections between all people associated with films and one depicting how the people all connected and the films they worked on together. Lastly, they utilized maps to show geographical expansion and locations by year for African American production companies.
Overall, I really enjoyed the presentation and display of the students database. The organization and tabs were extremely clear and the content pointed out some interesting new connections and analysis about African American race films- a topic I never particularly was interested in before. I think they did a great job in appealing to the general public and making traditional and complicated scholarship relevant to the average Joe. The dataset the students assembled has been licensed under a CC-BY 4.0 license, which allows the public to work with the data as long as they credited for their work. Additionally, they provided detailed guides on how to download, modify and cite the data and how to best present the data using graphs, maps, and other visualizations.
Link: http://dhbasecamp.humanities.ucla.edu/afamfilm/