For this week’s blog post, I chose to read the short story “That First Time” by Christopher Coake. This story appeared in 2007 in the Granta 97: Best of Young American Novelists 2 and uses third person narration to chronicle Bob “Bobby” Kline’s retrospective discovery after he is notified about the death of a woman whom he briefly hooked up with when he was 17 years old, Annabeth “Annie” Cole, by her best friend, Vicky Jeffords. Nearly 20 years later, Bob is forced to recognize his responsibility in breaking another’s heart, only to learn her best friend had been in love with her the whole time. The narrator illuminates the pain of death with the pain of divorce, using Bobby’s incipient divorce as a vessel for him to understand the depth of the pain of others.
Although there are very few characters in the story (relative to longer, more developed stories), I chose to first create my edge list based on character name and with whom they appeared in a scene or recalled memory with. Bobby Kline transitions between his qualms with the present to his qualms from his past, so I determined this a “scene” when characters were mentioned together. Additionally, I added a third column of weight, which is based on the number of scenes the characters appeared in together—the higher the number of scenes, the higher weight the relationship was given.
I created my network graph via Google Fusion Tables and can be seen below as well as accessed here. I chose to not change the color based on column because my network graph is only between unique characters and no other entities.
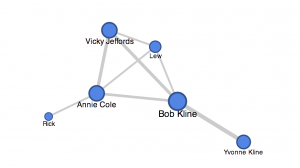
The size of the circle (node) is based on how many unique characters the person appeared in a scene with. For example, Bob, the main character by which the story is centered around, has the largest circle because he appears in a scene with nearly every character. Moreover, the width of the line extending between the nodes is my weight component from the edge list, so a thicker line denotes that the characters appeared in multiple scenes/memories with one another.
On an initial viewing of my network graph, one would be able to discern that Bobby is most likely the main character, due to the size of his node as well as the weights of his edges/lines. The interconnection between Annie, Vicky, Bobby, and Lew brings attention to a possible significant relationship. Yvonne is Bobby’s soon-to-be ex-wife, and my network graph shows how this relationship is significant (by weight) but also isolated from the rest of the characters.
I actually enjoy the shape my network graph took on because the square between Bobby, Annie, Vicky, and Lew almost resembles the table by which they sat at in a pizza restaurant during their adolescence in one of Bobby’s memories. This meeting ultimately transpired into Bobby and Annie’s brief and fleeting relationship that concluded in her heartbreak.
However, my network graph also has significant limitations that ought to be addressed. Although “That First Time” uses third person narration as its mode, the story is told through Bobby’s lens and thus the relationships are within that context. Rick the man who Annie married; however, my network graph shows this relationship as insignificant (if evaluated based on size and appearance). This is because Rick is briefly mentioned in the story, as most of it is recalled from a memory of being 17, which was before Annie met Rick. This limitation occurred based on the ontology I created for my edge list because I used “weight” based simply on how many scenes the characters appeared in together in the story. However, if I used weight based on my understanding of how “strong” the relationship is (i.e. marriage, engagement) then Rick and Annie’s relationship would appear much stronger.