For my story, the narrator does a great deal of introspection and has very little dialogue with other characters. Given the low number of characters in the story, I decided to include every single character that is mentioned by the narrator, even if it’s merely a single reference.
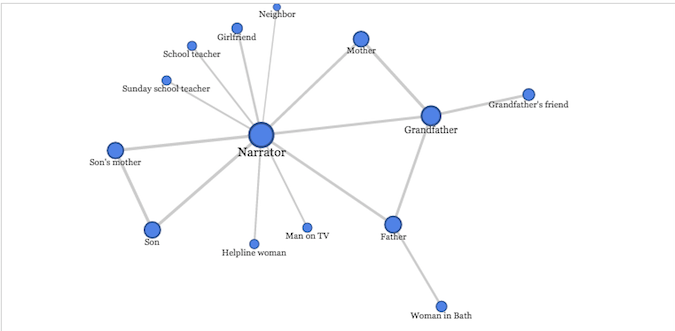
The story focuses around a family with three different generations suffering from PTSD after serving in war: the narrator, the narrator’s father, and the narrator’s grandfather. Interestingly, the network graph shows that the narrator and his grandfather have the most connections, and the father has one less edge than the grandfather, though it appears at first, from reading the story, that the father and the grandfather are given equal weight. Also, for the amount of time the narrator spends discussing his son and his son’s mother in the story, those two characters have no connections other than to the narrator and to each other.
One thing I think is interesting about the connections in this particular story is how they tie in to the subject matter: aside from their immediate families, none of the three men suffering from PTSD have any strong connections to other people. The narrator’s interactions with neighbors, teachers and counselors are shallow and artificial. The grandfather’s friend and the father’s acquaintance in Bath – their only non-familial connections – are both dead. I think this is a telling point about the sense of isolation that occurs with soldiers who return from war with PTSD; none of these three characters seem to fit in easily into civilian life, and their interactions with others are stilted and limited.