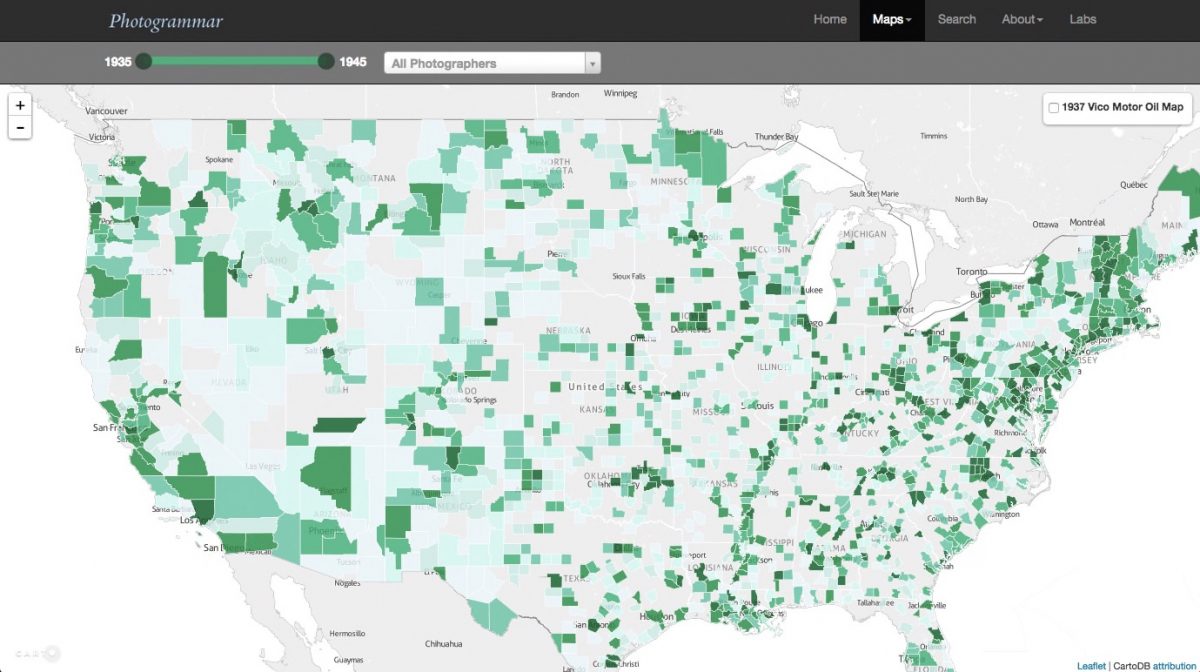
Today, I will be breaking down the website Photogrammer, a project backed by Yale and the National Endowment for the Humanities. Its main focus is a collection of 170,000 photographs that document life in America from 1935-1946.
This is the home page:

Sources
The photographs are sourced from collections belonging to the Farm Security Administration and Office of War Information, the Office of Emergency Management-Office of War Information Collection and from overseas sources. Photographers were sent across the country to document communities so as to guide and provide support for government programs. The dates of the photographs range from 1935 to 1946. All of the photos organized in this website are also maintained and catalogued by the Library of Congress.
Processes
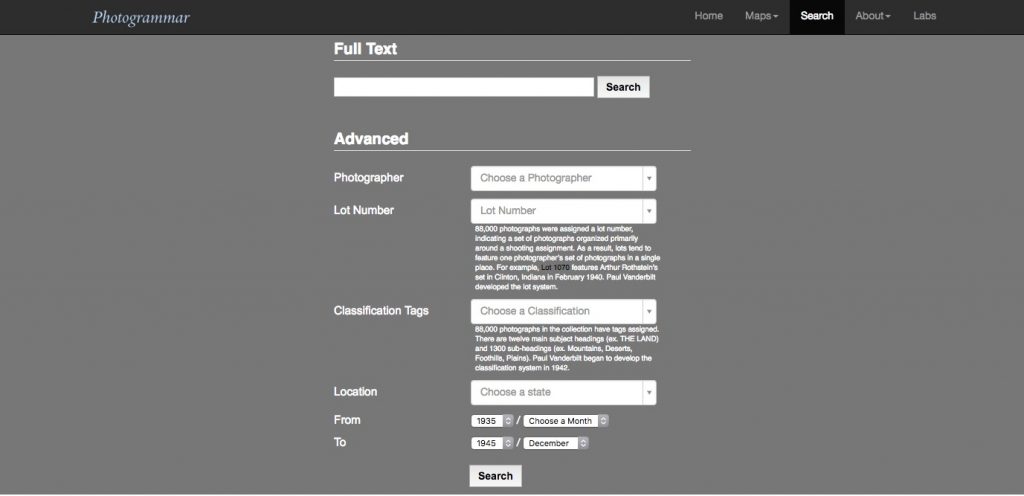
Pictured above is a search page that lists the various ways in which photos are categorized. The search variables include photographer, location, date, lot number and classification tags. The latter two are part of a classification system devised by Paul Vanderbilt for the FSA-OWI in 1942. Lots refer to sets of photographs taken by each photographer at a specific location and time. The classification tags allude to the subject matter of the photograph through 12 main headings such as “Work,” “Transportation,” and “War,” which have subheadings like “Agriculture: Crops, Livestock, Ranches,” which in turn has its own subcategories like “Cotton,” “Tobacco,” or “Wheat.”
All of this information was logged for each photo where possible (only 88,000 photos have a lot number and classification tags) to allow users to search. Another detail that doesn’t appear on this page is the call number for the photo at the Library of Congress. Since a lot of this information
Presentations
Clicking through “Start exploring” or on the “Interactive map” link on the homepage leads to this screen, which is the main visualization interface of the site:
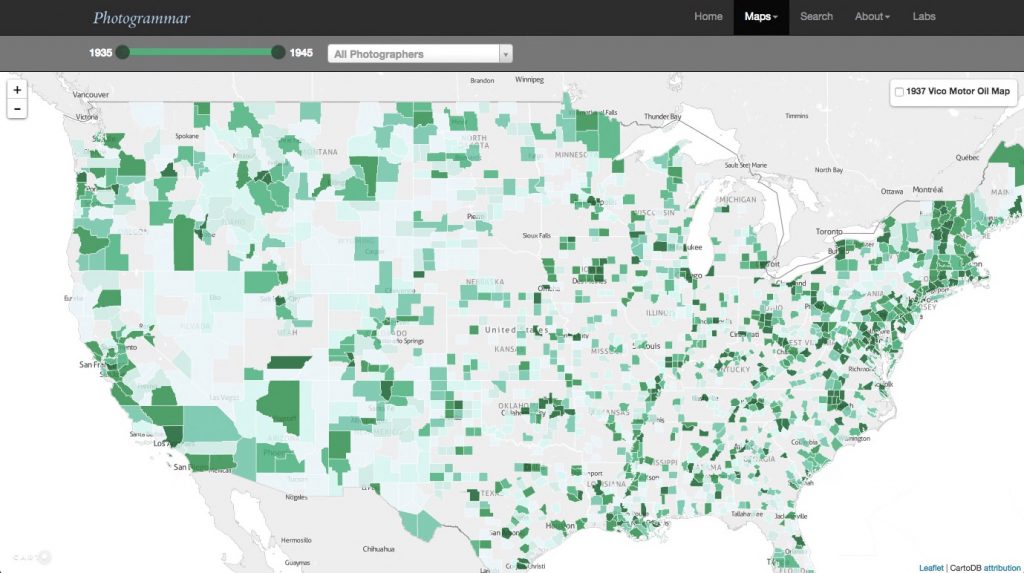
The interactive map allows users to select groups of photographs to view in various geographic locations and covers the 90,000 photographs of the collection that have geographical information. Zooming out allows users to see photos taken in the state of Alaska. Another option on the map allows users to see – as dots – the sets of photographs taken by specific photographers in each location. Clicking on the links opens up a new tab into a gallery of photographs.
Clicking on a single photograph in a gallery directs the user to the page displaying the photograph in detail as well as relevant information, and similar photographs.
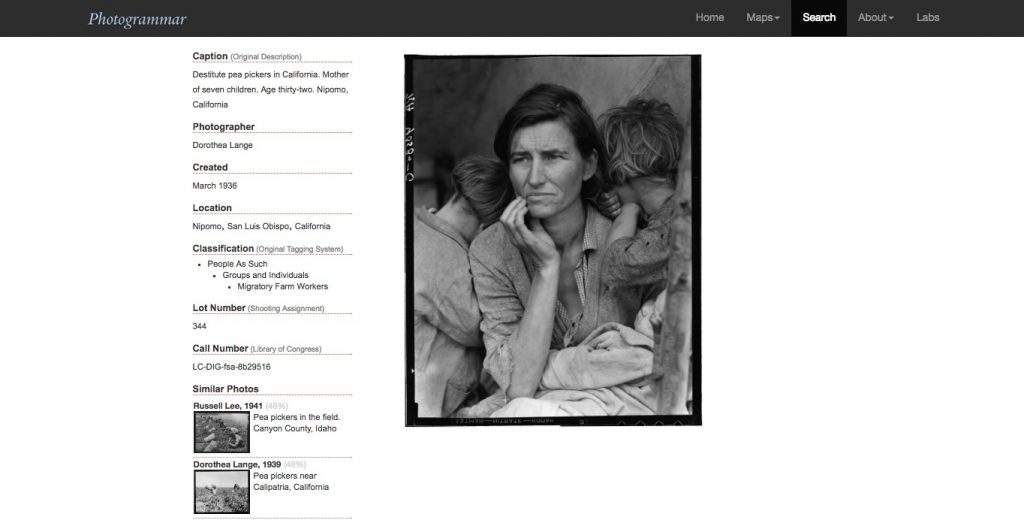
I found this famous photograph by accident as I was clicking through pages. It is one of my favourite photographs and I was pleasantly surprised to find it. As you can see, details of the photograph are presented next to it, including its call number at the Library of Congress.
Clicking on “Visualizations” from the home page to “Photogrammar labs” allows users to access various tools to visualize the data collected.
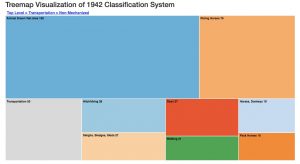
This includes a Treemap based on the Vanderbilt classification system for 88,000 photographs. Users are able to see the breakdown of how many photographs are in each category and subcategory, as well as access the photo galleries for the most specific sub-headings.

Another tool provides the metadata of photos in a specific state, although only data for California is available. Users can select one, several or all the counties where photos were taken, see the breakdown by year taken, photographer and classification heading.
One tool listed but unavailable is the ColorSpace, which is meant to categorize and summarize 17,000 color photographs based on hue, saturation and lightness.
Overall thoughts
This website had very interesting content and the designers put a lot of effort into sorting and visualizing the data for all these photographs. I felt that the classification tags could have been more clearly laid out, especially at the search page, because I wasn’t initially sure what tags were available. However, I really liked the interactive map and Treemap which helped me to gain an overview of the collection. I think this could be very useful for individuals who are looking for a specific set of photos within this collection as well as those who are curious about the collection, but found the Library of Congress’ site difficult to navigate.