In the Digital Harlem project, just under its title at the top, it reads “Everyday Life 1915-1930.” However, I argue, the map project doesn’t necessarily achieve this goal of presenting the everyday life of those who lived in Harlem during this time period, and, rather, skews the views of its viewers as to what that daily life would look like.
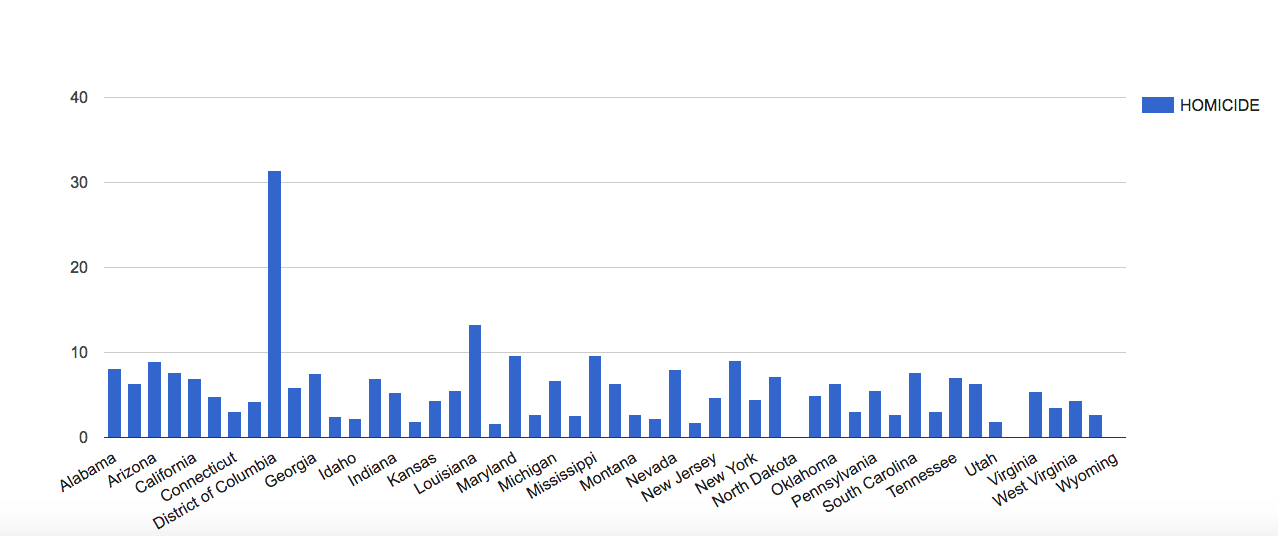
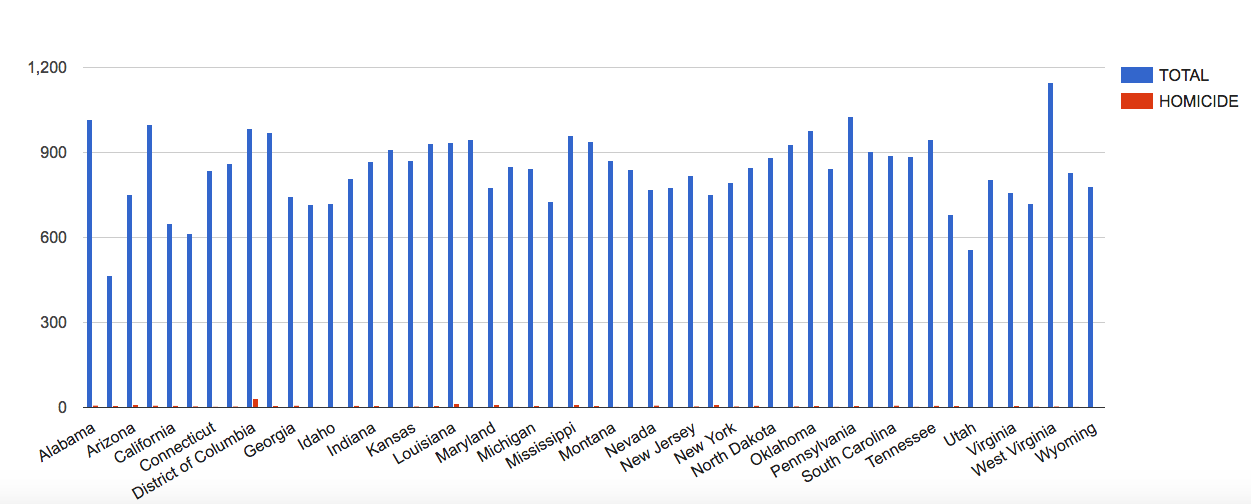
In the “Welcome” box, a description of the project reads that it gathered its data from legal records, newspapers, and other archived and published sources and it says from that we can draw conclusions about Harlem’s every day life. When someone looks at legal records, they are solely looking at crimes that happened, rather than simply everything going on in Harlem. From my previous blog post, I discussed how looking only at a homicide data visualization would make a person assume that homicide is a major cause of death in America. The same goes here for crime. If we look at crime and legal records as a descriptor of the Harlem community, that would cause us to assume crime is a major factor in their everyday lives, even though there is a high chance that is not true.
Furthermore, in using newspaper clippings, there is a lack of “everyday” realism to this project. Newspaper clippings are written about noteworthy pieces of information that the people living everyday lives would want to know. Often, in newspapers, individuals aren’t learning about the everyday things. They wouldn’t read that Jimmy ate a bowl of cereal for breakfast, because that isn’t news-worthy. Rather, they learn about such and such crime or scandal, or even the major accomplishments of the community, neither of which fall in the realm of everyday life.
Then, should you choose the Numbers Arrests map option on the right, a slew of dots will pop up, and if you click some of them, you will find that many cases shown were dismissed. In looking at cases that were dismissed, we get a further skewed view about the amount of crime in the area, thus further skewing our idea of what conflicts arise in Harlem’s “everyday life.” If you look at the top, you can mark black settlement in the area to layer with the number arrests, which seems to make a mental connection between black settlement and crime in Harlem, which may not be a fair image to create for the everyday lives of the people of Harlem.
Then, if you go to January 1925, the description itself says it left out recurrent events, which is at the core of what “everyday life” is, it is a series of recurrent events. It seems almost ridiculous that recurrent events like church services would be left out, because church is clearly an important part of these individuals’ lives. The fact that they selected to leave out key sets of data further emphasizes the sense of agenda laced into this map. Instead of the daily activities, we get who was murdered where, who robbed who, and who was arrested for prostitution with the occasional alumni club meeting thrown in. This isn’t the everyday life.
For the site, in its About, to say it is about “the lives of ordinary African New Yorkers” is simply preposterous and, to be honest, angering. Rather, they try to argue that out of the “suffering” these Harlemites are facing, they turn to crime, but that narrative is lost. We learn nothing of the daily life, the family life, the work life, of these individuals. Had this map incorporated family photos, personal narratives, films, and other information about this area, I might’ve found it to be more true to these Harlemites’ daily lives.