Week 1 – Inventing Abstraction
Inventing Abstration, 1910-1925 is an online visualization that accompanies a physical exhibit at the New York Museum of Modern Art. It was displayed at the MOMA from December 23, 2012 to April 15, 2013. The exhibit aimed to capture and understand the beginnings of the abstract art movement. Included in the exhibit were paintings, drawings, books, sculptures, films, photographs, sound poems, atonal music, and non-narrative dance.

Another purpose of the exhibit was to see how the abstract art movement was able to move so quickly between regions and artists. I thought this visual representation was a great way of doing that. The visualization displayed artists as nodes and they connected to other nodes if they had verifiable interaction.
Credit is given to Second Story for the design and development of the project. As stated previously, the exhibit brought together art of many different formats as sources. These art works are then digitized via photographs and scans. Once these works have been processed, they are matched with the respective artists. In terms of the nodes and links, the visualization looks like it was made in the program, Gephi. To construct these visual networks, points of data are inputted into an excel sheet and exported as a csv file. In the excel sheet are most likely categories such as “connections” or “art work.” This allows the artists to be connected via the links.
The network map allows users to click around the various nodes. When a node is clicked, the screen zooms in to the specific node and every node that is connected. This creates a smaller network within the overall network. From here, users can see which artists are associated with one another. In addition to this, this screen shows more details of artists such as their works, birthplace, interests, and more. The zoomed in networks are also a component of Gephi, but additional software was most likely used to add in the descriptions on the side.

As with many network visualizations, it can be a bit overwhelming to look at. I feel that the more heavily weighted artists should have been a different color than red, especially since the links were red. It tends to look a bit messy when scrolling around on the zoomed out view. It is not as bad when zoomed in. However, the website also provides users with another way of viewing the artists. There is an “artists” tab that lets users scroll through in alphabetical order. There are also additional tabs for “conversations” and “programs and events” which go further in depth with the works.
Overall, I found the UI of the project to be pretty self-explanatory. The only thing I would have changed are the colors of the visualization. As far as UX is concerned, I think network maps such as these can be intimidating, and not user-friendly to people unfamiliar with them. I think the project as a whole was quite interesting, and I enjoyed going through it all.


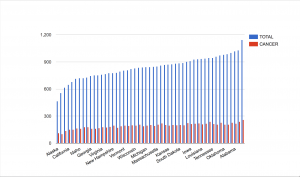
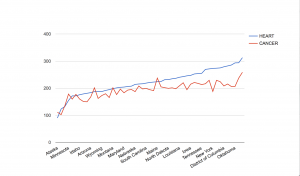
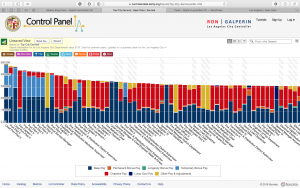 Some people that may find this data useful are city officials who are in charge of the budget, and also taxpayers. City officials can see how much of the budget is going to what positions and how they affect the city as a whole. Taxpayers can see where some of their tax dollars are going, and how the city of LA is paying its workers. I would imagine people would wonder why some positions get so much bonus pay. The job descriptions and years of experience are missing from the data set. This would help to differentiate the positions and give context as to why they are being paid so much. This also helps in comparison. For instance, why does a port pilot make significantly more than firefighters or police officers?
Some people that may find this data useful are city officials who are in charge of the budget, and also taxpayers. City officials can see how much of the budget is going to what positions and how they affect the city as a whole. Taxpayers can see where some of their tax dollars are going, and how the city of LA is paying its workers. I would imagine people would wonder why some positions get so much bonus pay. The job descriptions and years of experience are missing from the data set. This would help to differentiate the positions and give context as to why they are being paid so much. This also helps in comparison. For instance, why does a port pilot make significantly more than firefighters or police officers?