This week I decided to examine a short story called First Semester by Rachel B. Glaser and John Maradik, found within Granta 136: Legacies of Love online. The method of analysis I chose to use was a network visualization.
This short story predominantly focuses on the perspective of the main character Sarah who has just recently started her freshmen semester of college and describes her initial experiences as she grows throughout the semester. It follows her pursuits through her various relationships with other students often angled in terms of her sexual development throughout the semester and how that also affects her mental state as well.
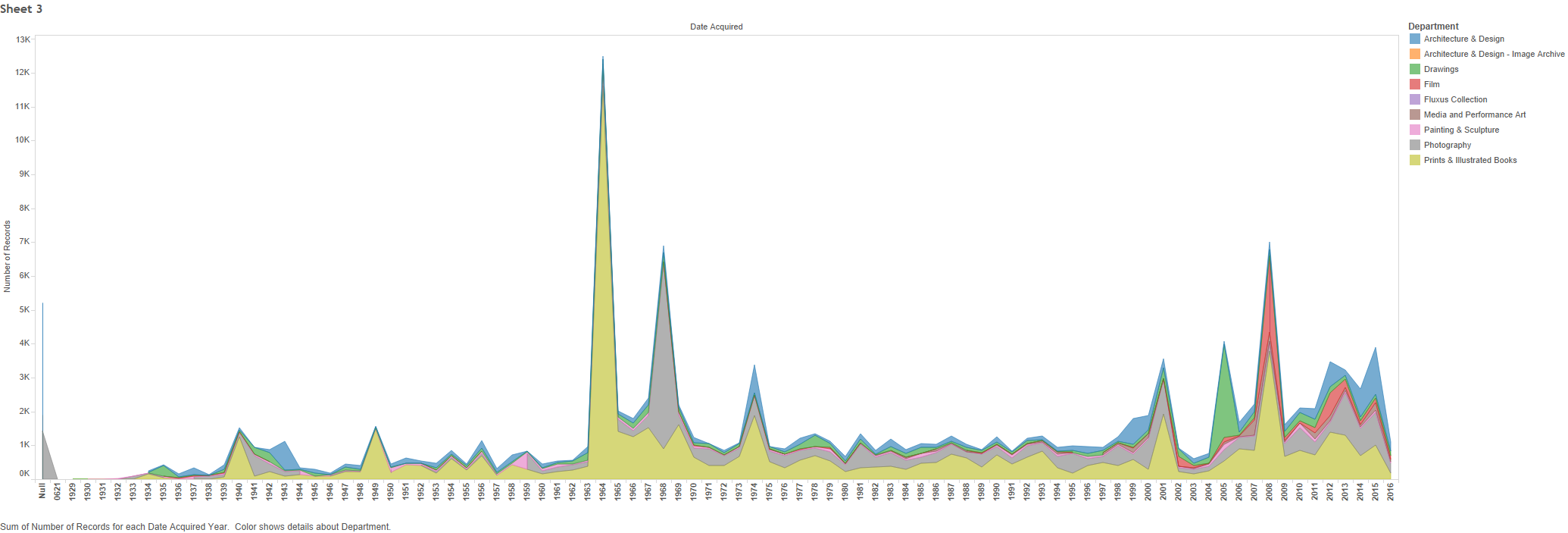
In order to examine this story I broke out my network visualization by looking at any direct interaction of a relevant character vital to the current scene as a guideline for my edge list. Examining the visualization, it points out how Sarah is the predominant main character in terms of interactions with others throughout the various scenes of the story. It also points out how there is somewhat of a social group/circle among Sarah, David, Colin, and The Pip (The opposite worlds girl).
The visualization does lack however in identifying how weak or strong a connection between characters might be. It doesn’t include a weighting system to distinguish relationships that are weak, for example Sarah’s brief conversation with the petworld employee, versus a stronger bond like Sarah’s relationship between herself and David. If I were to fix this issue for a further iteration of the network graph I would try to establish a weighting system that used the number of scenes that two characters interacted within to distinguish between the various spectrum of relationship strength.